DataScientists: a blog about everything data related.
-
Data Engineer – The Top 10 Books to read in 2023
Whether you are just starting out as a data engineer or you are an old pro it is always important to stay up to date on trends and technologies. In this post I will talk about the top 10 books every data engineer should read in 2023 to keep their skills fresh. Data Science from […]
-
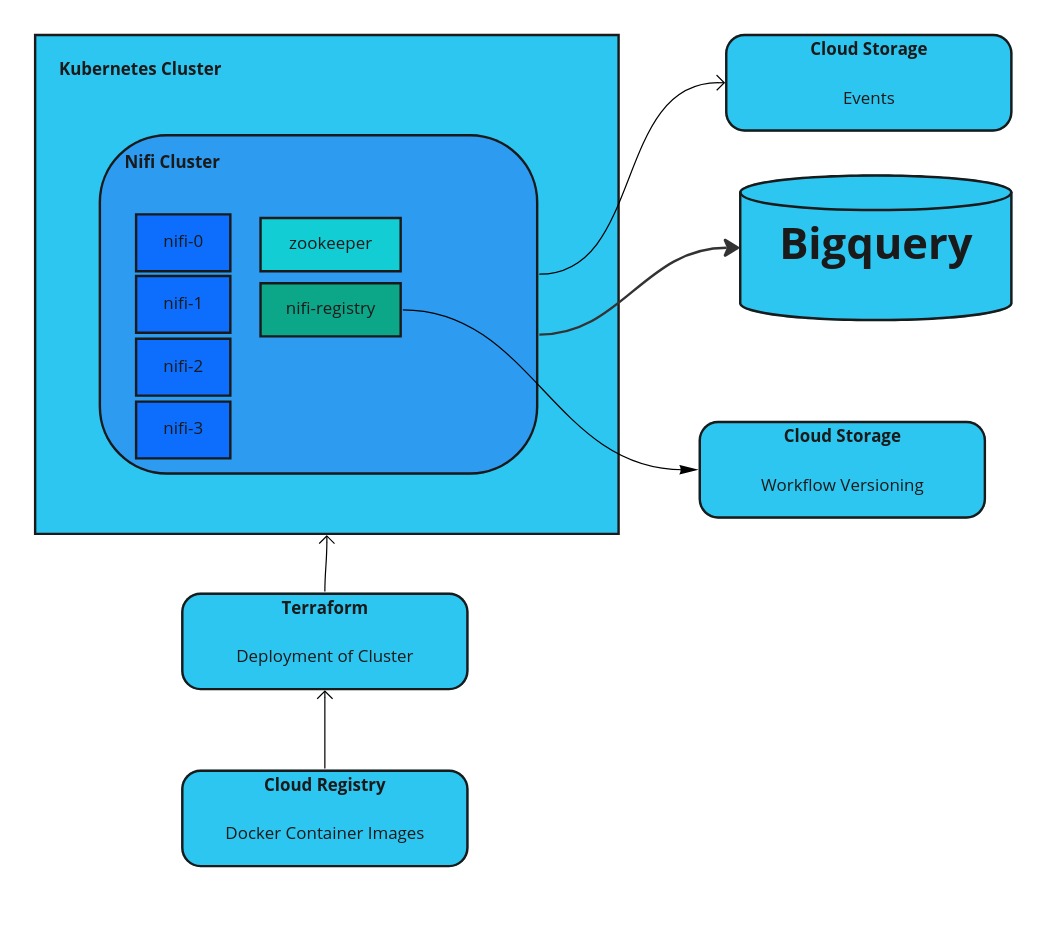
Apache Nifi on Google Cloud Kubernetes Engine (GKE)
Apache Nifi on GKE can be a good solution, if you want to have a low code solution for processing streaming data. If you set it up on GKE, a managed version of Kubernetes, you have a managed scalable environment and do not need to worry about handling the actual servers. Setup of the Apache […]
-
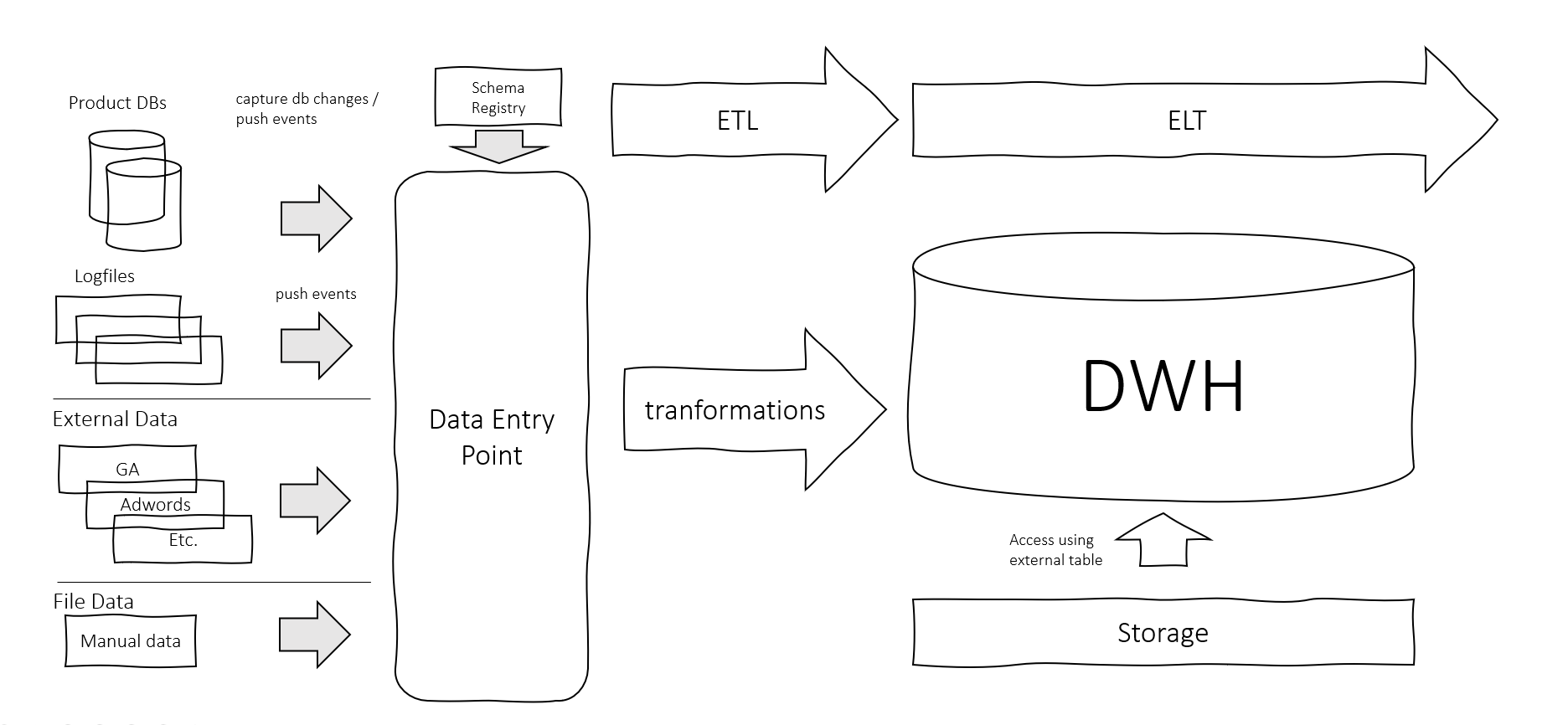
Data Infrastructure in the Cloud
Having your data infrastructure in the cloud has become a real option for a lot of companies, especially since the big cloud providers have a lot of managed services available for a modern data architecture aside from just a database management system.
-
Bringing machine learning models into production
Developing and bringing machine learning models into production is a task with a lot of challenges. These include model and attribute selection, dealing with missing values, normalization and others. Finding a workflow that puts all the gears, from data preprocessing and analysis over building models and selecting the best performing one to serving the model […]
-

Google Cloud Data Engineer Exam Preparation
This is a little text with all the stuff that helped me prepare for the Google Cloud Data Engineer Exam. There are a lot of courses and resources, that help you in preparing for this. The following links helped me in preparation for my Google Data Engineer Exam. On Coursera there is are several courses […]
-
AVRO schema generation with reusable fields
Why use AVRO and AVRO Schema? There are several serialized file formats out there, so chosing the one most suited for your needs is crucial. This blog entry will not compare them, but it will just point out some advantages of AVRO and AVRO Schema for an Apache Hadoop ™ based system. Avro schema can […]
-
Plumber: Getting R ready for production environments?
R Project and Production Running R Project in production is a controversially discussed topic, as is everything concerning R vs Python. Lately there have been some additions to the R Project, that made me look into this again. Researching R and its usage in production environments I came across several packages / project, that can […]
-
Analytics Platform: An Evolution from Data Lake
Analytics Platform Having built a Data Lake for your company’s analytical needs, there soon will arise new use cases, that cannot be easily covered with the Data Lake architecture I covered in previous posts, like Apache HAWQ™: Building an easily accessable Data Lake. You will need to adapt or enhance your architecture to become more […]
-
Building a Productive Data Lake: How to keep three systems in sync
Three Systems for save Development When you are building a productive Data Lake it is important to have at least three environments: Development: for development, where “everything” is allowed. Staging: for testing changes in a production like environment. Production: Running your tested and productive data applications With these different environments comes the need to keep […]
-
Apache AVRO: Data format for evolution of data
Flexible Data Format: Apache AVRO Apache AVRO is a data serialization format. It comes with an data definition format that is easy to understand. With the possibility to add optional fields there is a solution for evolution of the schemas for the data. Defining a Schema Defining a schema in Apache AVRO is quite easy, […]
Got any book recommendations?