Category: Data Lake
-
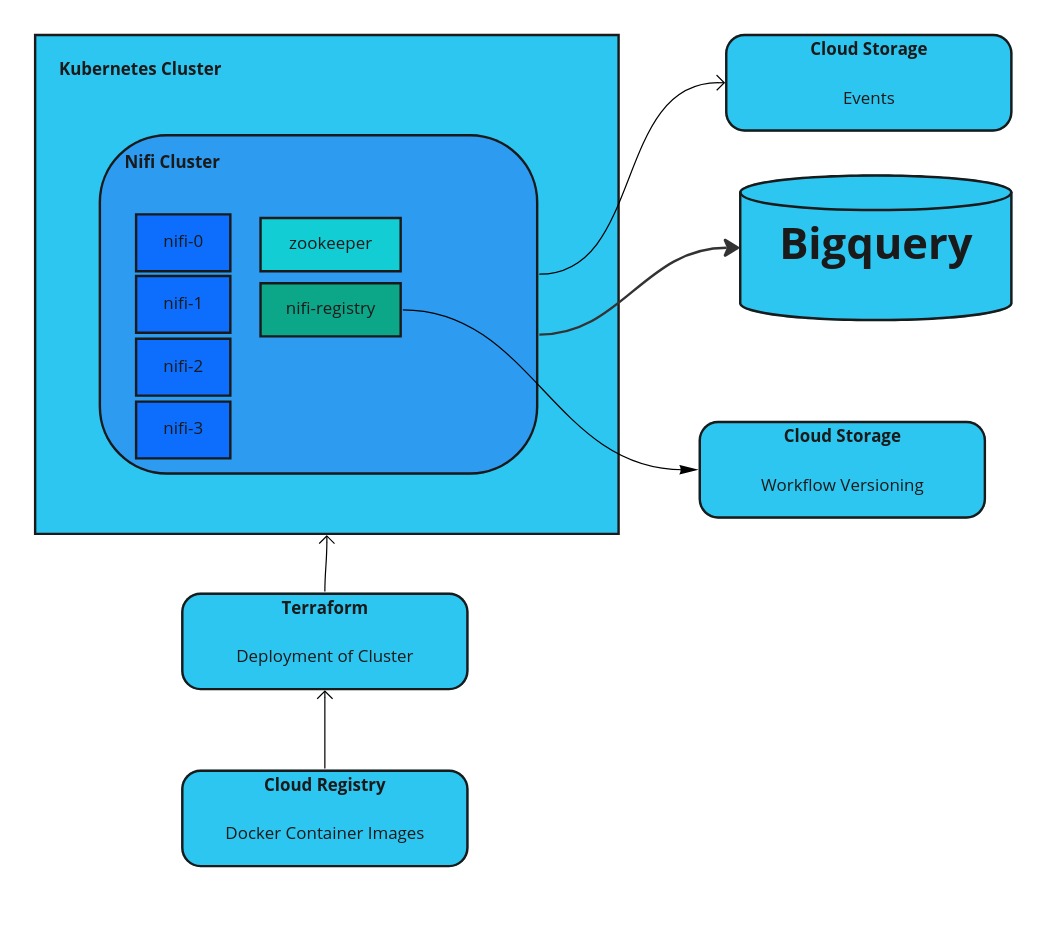
Apache Nifi on Google Cloud Kubernetes Engine (GKE)
Apache Nifi on GKE can be a good solution, if you want to have a low code solution for processing streaming data. If you set it up on GKE, a managed version of Kubernetes, you have a managed scalable environment and do not need to worry about handling the actual servers. Setup of the Apache…
-
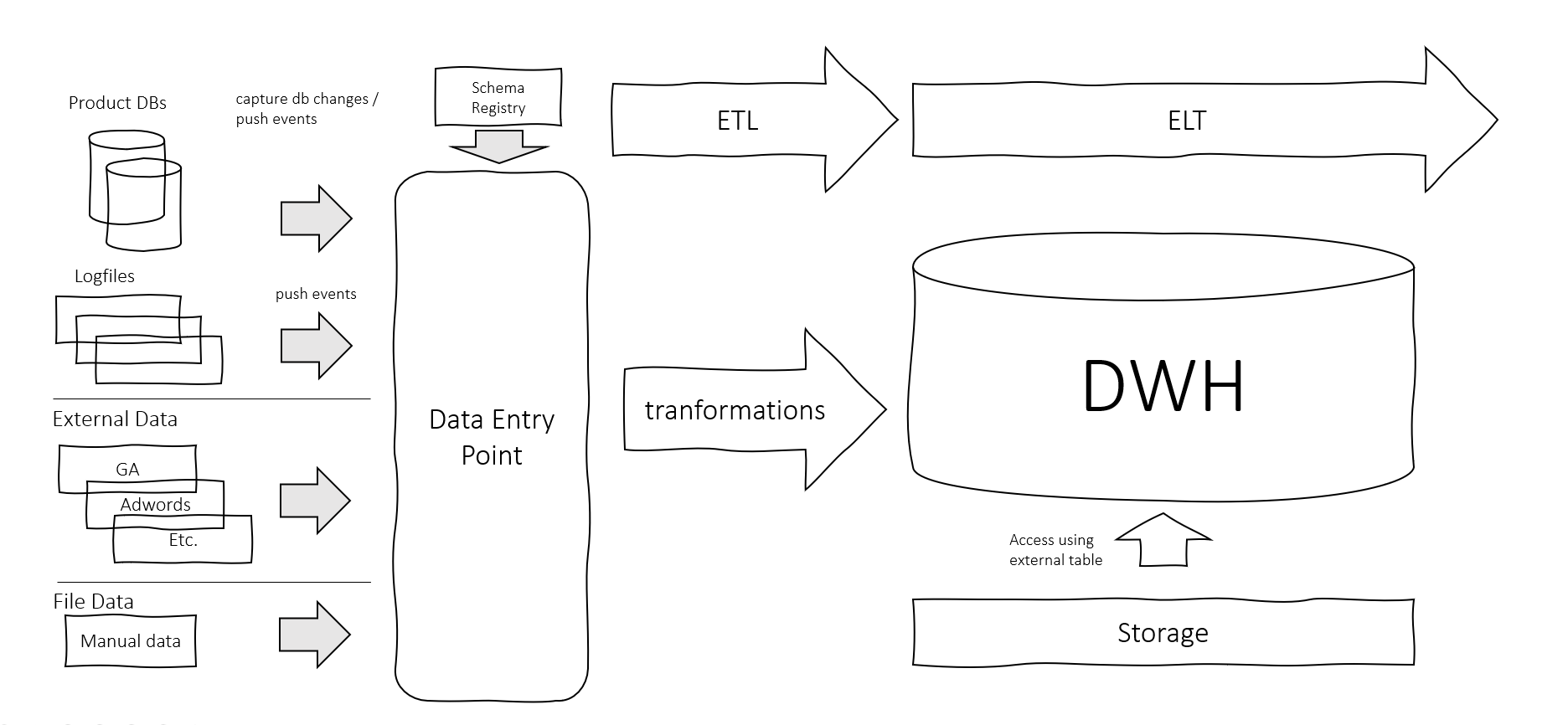
Data Infrastructure in the Cloud
Having your data infrastructure in the cloud has become a real option for a lot of companies, especially since the big cloud providers have a lot of managed services available for a modern data architecture aside from just a database management system.
-
AVRO schema generation with reusable fields
Why use AVRO and AVRO Schema? There are several serialized file formats out there, so chosing the one most suited for your needs is crucial. This blog entry will not compare them, but it will just point out some advantages of AVRO and AVRO Schema for an Apache Hadoop ™ based system. Avro schema can…
-
Analytics Platform: An Evolution from Data Lake
Analytics Platform Having built a Data Lake for your company’s analytical needs, there soon will arise new use cases, that cannot be easily covered with the Data Lake architecture I covered in previous posts, like Apache HAWQ™: Building an easily accessable Data Lake. You will need to adapt or enhance your architecture to become more…
-
Building a Productive Data Lake: How to keep three systems in sync
Three Systems for save Development When you are building a productive Data Lake it is important to have at least three environments: Development: for development, where “everything” is allowed. Staging: for testing changes in a production like environment. Production: Running your tested and productive data applications With these different environments comes the need to keep…
-
Apache HAWQ: Building an easily accessable Data Lake
Data Lake vs Datawarehouse The Data Lake Architecture is an up and coming approach to making all data accessible through several methods, be that in real-time or batch analysis. This includes unstructured data as well as structured data. In this approach the data is stored on HDFS and made accessible by several tools, including: Apache…