With Hadoop 2.0 and the new additions of Stinger and Impala I did a (not representive) test of the performance on a Virtual Box running on my desktop computer. It was using the following setup:
- 4 GB RAM
- Intel Core i5 2500 3.3 GHz
The datasets were the following:
- Dataset 1: 71.386.291 rows and 5 columns
- Dataset 2: 132.430.086 rows and 4 columns
- Dataset 3: partitioned data of 2.153.924 rows and 32 columns
- Dataset 4: unpartitioned data of 2.153.924 rows and 32 columns
The results were the following:
| Query | Hive (0.10.0) | Impala | Stinger (Hive 0.12.0) |
|---|---|---|---|
| Join tables | 167.61 sec | 31.46 sec | 122.58 sec |
| Partitioned tables Dataset 3 | 42.45 sec | 0.29 sec | 20.97 sec |
| Unpartitioned tables Dataset 4 | 47.92 sec | 1.20 sec | 36.46 sec |
| Grouped Select Dataset 1 | 533.83 sec | 81.11 sec | 444.634 sec |
| Grouped Select Dataset 2 | 323.56 sec | 49.72 sec | 313.98 sec |
| Count Dataset 1 | 252.56 sec | 66.48 sec | 243.91 sec |
| Count Dataset 2 | 158.93 sec | 41.64 sec | 174.46 sec |
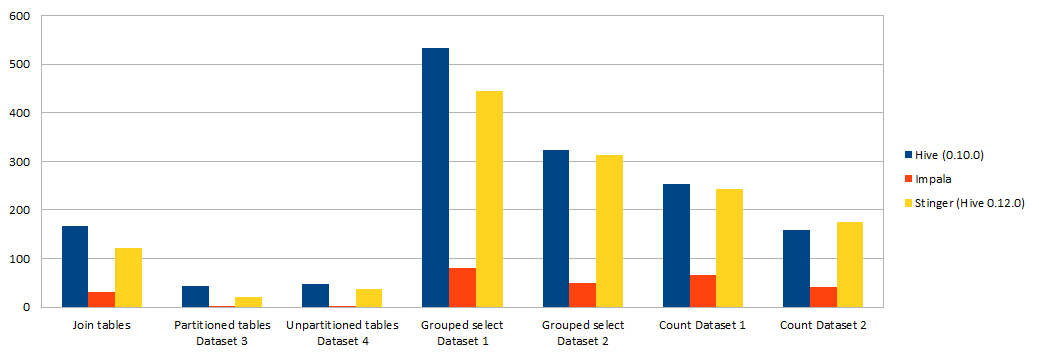
This shows that Stinger provides a faster SQL interface on Hive, but since it is still using Map / Reduce when calculating data it is no match for Impala that doesn’t use Map / Reduce. So using Impala makes sense when you want to analyse data in Hadoop using SQL even on a small installation. This should give you easy and fast access to all data stored in your Hadoop cluster, that was before not possible.
Facebook’s Presto should achieve nearly the same results, since the underlying technique is similar. These latest additions and changes to the Hadoop framework really seem like a big boost in making this project more accessible for many people.
Leave a Reply