Why use AVRO and AVRO Schema?
There are several serialized file formats out there, so chosing the one most suited for your needs is crucial. This blog entry will not compare them, but it will just point out some advantages of AVRO and AVRO Schema for an Apache Hadoop ™ based system.
- Avro schema can be written in JSON
- Avro schema is always present with data, getting rid of the need to know the schema before accessing the data
- small file size, since schema is always present there need to be stored less type information
- schema evolution is possible by using a union field type with default values. This was explained here. Deleted fields also need to be defined with a default value.
- Avro files are compressible and splitable by Hadoop MapReduce and other tools from the Hadoop universe.
- files can be compressed with Snappy and Deflate.
AVRO Schema generation
Generating Apache AVRO ™ schemas is pretty straight forward. They can be written in JSON and are always stored with the data. There are field types for everything needed, even complex types, such as maps and arrays. A schema can also contain a record, which is in itself an independent schema, as a field. This makes it possible to store data of almost unlimited complexity in AVRO. In case of very complex schema definitions keep in mind, that to access complex data structures can be very expensive later on in the process of transforming and working with such data. Here are some examples of AVRO supported datatypes
AVRO Datatypes
- Primitive types as null, integer, long, boolean float, double, string and byte
- Complex types such as records. This fields are basically complete schemas in their own right. These fields consist of:
- name
- namespace
- fields
- Enums
- Arrays
- Maps
- Fixed length fields
- Logical datatypes
Logical datatypes are something special and by using these you can define other fields you might need. As you can see in the list above there is no datatype for date or datetime. These are implemented using logical datatypes. Define a logical type like this:
{ "type": "bytes", "logicalType": "decimal", "precision": 4, "scale": 2 }
Supported logical datatypes are decimal, date, time, timestamp and duration.
Downsides in Schema Generation
There is one downside though, namely that individual fields are not reusable. This topic was addressed by Treselle Systems in this entry. They introduce a way to make fields in a AVRO Schema reusable by working with placeholders and then replacing them with before defined subschemas. This comes in handy when you have fields, that should be available in each AVRO schema, such as meta information for a message pushed into your system.
AVRO Schema Generator
To make AVRO Schema generation more comfortable, I worked on a project, inspired by Treselle Systems’ text and combined it with other tools I use daily:
- Jupyter Notebook
- AVRO-Doc: a JS based server reformatting AVRO schemas into an easily readable HTML format.
- AVRO schema repo server: a simple REST based server to publish schemas to and provide them for all parties that generate and consume the data stored in AVRO format
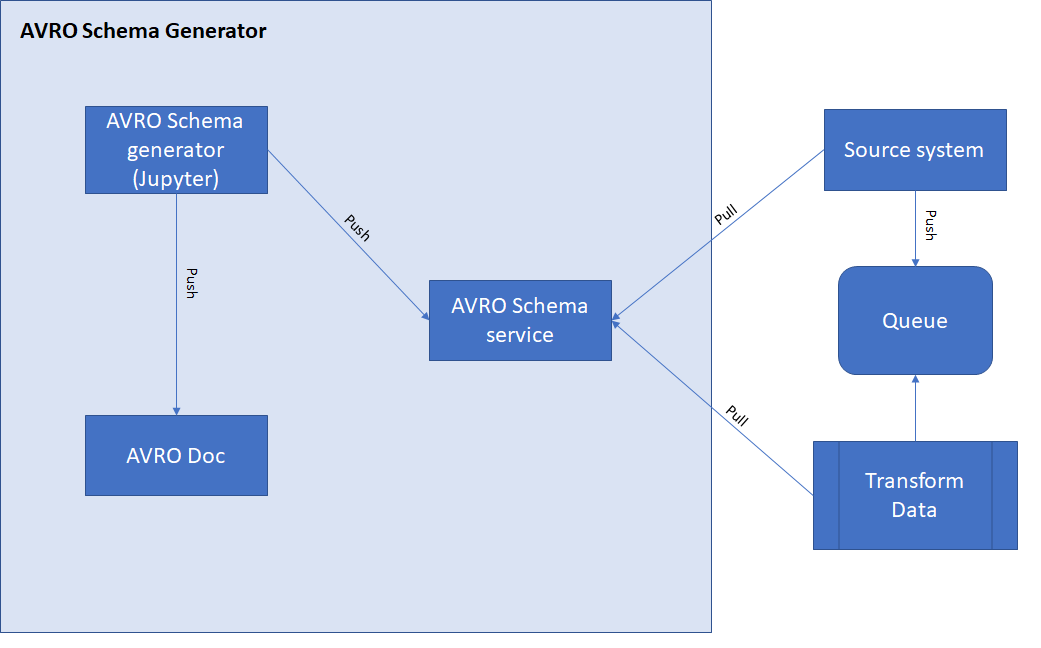
This combination of several tools makes it possible to handle data more easily.
Schema generator
Schemas are written using a Jupyter notebook server. The project contains:
- AVRO Schema Editor.ipynb: To create new schemas and adapt existing ones. You load the existing files into the notebook and then edit them before saving them to file again.
- Avro Schema Generator.ipynb: This notebook checks schema syntax and replaces subschemas in a generated version of the schema. Subschemas need to be defined before generating a final version of a schema. This notebook also implents functions to upload the schemas to the repository server.
- Docker file for setting up the schema repository server in
docker_schema_repo. Make sure to set the correct URL before trying to upload the generated schemas. - Docker file for setting up the avrodoc server, with built in active directory plugin in Nginx. Find this file in
docker_avrodoc
The project contains an example schema for reference.
Schema repository
The schema repository provides a generally available schema store. This store has a built-in version control. It helps sources to take their time adapting to a new version of the schema.
This asynchronity is possible, because all schemas are compatible with previous version. With that restraint it is also possible to have different sources push one schema in different versions and still be able to transform the data using one process. Not existing values in different version of a schema are filled with the mandatory default value and this default value can even be NULL.
Conclussion
This project aims to help managing data definitions in Hadoop based systems. With the schema repository it provides a single source of truth for all data definitions, at least for data entry and if you decide to use AVRO schemas thourghout your system, even after transformation, you can manage all data definition here.
There are several other schema repositories out there, that can be used, e.g. the one provided by Confluent or the one introduced by Hortonworks for Apache Nifi. The tools used here are just examples of how such a system can be set up and how to introduce reusable AVRO fields into your schemas.
The code can be found in our repository.