A dbt Ops Agent Case Study
A small, well-instrumented workflow can turn dbt failures into reviewable Git changes by combining deterministic parsing, constrained LLM tooling, and VCS-native delivery — while preserving governance through traces, guardrails, and CI. This is a blueprint to build a first Production-Grade GenAI Agent.
You can find the complete implementation and reusable blueprint for this Production-Grade GenAI Agent on GitLab.
Executive Summary (Leadership + Technical TL;DR)
What you’ll ship
A production-ready CLI/worker that monitors dbt execution environments to:
- Detect: Isolate the specific failing model and error signature from raw dbt.log artifacts.
- Generate: Synthesize a structured fix proposal using PydanticAI to enforce strict type safety and tool-calling reliability.
- Test: Run dbt compile on the LLM generated fix
- Deliver: Open a GitLab Merge Request (MR) containing the proposed patch, explanation, and trace links.
- Audit: Emit end-to-end traces for every reasoning step, ensuring full accountability and a path for optimization.
Why it matters
- MTTR Reduction: Eliminates the manual “context-switching tax” of locating files and opening boilerplate MRs.
- Governance Preserved: AI acts as a “drafting assistant,” not a committer. Human review remains the final gate.
- Operational Visibility: Transforms “black box” AI into a measurable pipeline with distinct success/failure metrics.
What makes it “scalable GenAI”
This system moves beyond simple chat interfaces. It utilizes PydanticAI’s structured result types, dependency injection for unit-testable context, and deterministic workflow graphs to ensure reliability at an enterprise level.
Problem Framing: dbt Failures Are an Ops Workflow
The reality in mature data orgs
In high-volume data platforms, dbt runs fail frequently due to upstream schema changes or minor logic drifts. The “fix” is often trivial, but the workflow glue is expensive. Engineers spend 80% of their time identifying the failing file, checking out a branch, and navigating the repository structure rather than solving the logic.
What we should automate (and what we should not)
- Automate: Error detection, context gathering (fetching relevant .sql and .yml files), patch packaging, and MR creation.
- Do Not Automate: Silent pushes to production, sweeping architectural refactors, or changes to sensitive financial logic without human oversight.
“We’re not automating decisions; we’re automating the path to a decision.”
System Overview (Architecture + Responsibilities)
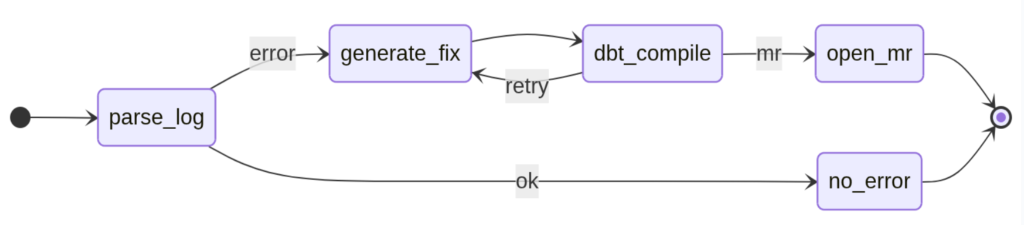
Components and boundaries
- Parser: A deterministic Python module that regex-extracts the failing model name and error snippet.
- Agent (PydanticAI): A typed agent that takes the error context and returns a validated FixProposal object.
- VCS Delivery: A wrapper for the GitLab API to handle branch creation and MR documentation.
- Observability: A tracing layer to record every LLM input and output for auditability.
Designing for Resiliency with Workflow Graphsy
In simple scripts, a failure at any step (like a network timeout or a hallucinated SQL syntax) kills the process. For a production ops agent, we use a Workflow Graph approach. This allows us to handle non-linear logic—specifically the “Retry Loop” when an AI-generated fix fails to compile.
Why this architecture works:
- Early Exit: If parse_log returns ok, the system terminates immediately at no_error, saving compute and LLM tokens.
- The Validation Loop: By connecting dbt_compile back to generate_fix with a retry edge, we give the agent a second chance. We can pass the compiler error back to the LLM as feedback, allowing it to self-correct before a human ever sees the code.
- State Management: Each node in this graph only needs to know about the data passed from the previous node, making the system modular and significantly easier to unit test.
Core Design Pattern: “Constrain + Structure + Trace”
Constrain: Reduce the agent’s degrees of freedom
Do not give the agent a “search the whole repo” tool. Feed it only the specific failing .sql file and its immediate sources.yml. This prevents the agent from getting “lost” in large monorepos and reduces token costs.
Structure: PydanticAI Result Types
Instead of parsing raw JSON strings from an LLM, we use PydanticAI’s result_type. This ensures that the agent cannot return a response unless it fits our strict operational schema.
@dataclass(frozen=True) class FixDeps: config: Config model_path: str @property def dbt_base_path(self) -> Path: return Path(self.config.dbt_base_path) @property def model_full_path(self) -> Path: return self.dbt_base_path / self.model_path @property def sources_full_path(self) -> Path: # Note: In a real monorepo, you might resolve this dynamically return self.dbt_base_path / "models/data_project/sources.yml"
Step-by-Step Deep Dive
Step 1 — Parsing the dbt log: Deterministic and reliable
LLMs are overkill for log parsing. Use a deterministic parser to identify the ERROR block. This ensures 100% reliability in identifying the target model.
pattern = r”[error].?ERROR creating.?model ([^\s]+)”
match = re.search(pattern, content, re.DOTALL | re.IGNORECASE)
Step 2 — Context assembly: The “minimum viable evidence”
Provide the “Triple Threat” of context: The Error, the current Model SQL, and the Source Schema. Using PydanticAI Dependencies, we can inject these files into the agent’s context at runtime.
Step 3 — Fix generation: The PydanticAI Agent
The agent’s job is not to “talk”; it’s to produce a structured patch proposal.
fix_agent = Agent( model="openai:gpt-4", output_type=DbtFix, deps_type=FixDeps, instructions=system_prompt, ) @fix_agent.tool @observe(name="tool.read_model_file") async def read_model_file(ctx: RunContext[FixDeps]) -> str: """Reads the dbt model currently being analyzed.""" return ctx.deps.model_full_path.read_text(encoding="utf-8") @fix_agent.tool @observe(name="tool.read_source_definitions") async def read_source_definitions(ctx: RunContext[FixDeps]) -> str: """Reads the project's sources.yml to verify available source columns.""" return ctx.deps.sources_full_path.read_text(encoding="utf-8")
Step 4 — Validation: The agent as a tester
Before the MR is even opened, run dbt compile –select <model>. If the AI’s “fix” doesn’t even compile, don’t waste a human’s time— the agent then retries to generate the fix, giving the new error message as additional information.
Pro Tip: When dbt compile fails, capture the stderr. Feed that specific error message back into the PydanticAI agent’s next prompt. This “Reflection” pattern often turns a 70% success rate into 95%+.
dbt_project_dir = Path(self.config.dbt_base_path).resolve() model_path = fix.model_path model_full_path = (dbt_project_dir / model_path).resolve() # Write the fixed SQL into the local workspace so compile validates what we will ship model_full_path.parent.mkdir(parents=True, exist_ok=True) model_full_path.write_text(fix.fixed_sql.rstrip() + "\n", encoding="utf-8") # Run dbt compile (use cwd to ensure dbt_project.yml is found) cmd = [ "dbt", "compile", "--project-dir", str(dbt_project_dir), "--profiles-dir", str(dbt_project_dir), "--select", f"path:{model_path}", ]
Step 5 — Delivery via GitLab MR: The agent as a teammate
Assign the MR to the data engineer responsible for that domain. Use a clear naming convention: fix/ai-proposal-fct-orders-170605.
model_slug = fix.model_path.split("/")[-1].replace(".sql", "") run_suffix = time.strftime("%Y%m%d-%H%M%S") branch_name = f"fix/{model_slug}/{run_suffix}" # Base the branch on the latest main SHA on the server. main_branch = project.branches.get("main") main_sha = main_branch.commit["id"] try: project.branches.create({"branch": branch_name, "ref": main_sha}) except gitlab.exceptions.GitlabCreateError as e: msg = str(e).lower() if e.response_code in (400, 409) and ("already exists" in msg or "branch" in msg): print(f"Branch {branch_name} already exists, using existing branch.") project.branches.get(branch_name) else: raise
Operational Visibility: Peeking Under the Hood
While the workflow graph provides the structure, Langfuse provides the “black box” recording of what actually happens inside the LLM’s reasoning steps. This is the difference between a script that “just runs” and a system that can be audited for production use.
The Trace View: Tracking the Thought Loop
By instrumenting the agent with the @observe() decorator, we capture every turn of the conversation. This is especially critical during the Step 4 Validation Loop.
- Auditability: If a generated fix fails, we can see the exact stderr from dbt and how the agent parsed it to attempt a second fix.
- Prompt Iteration: We can compare different versions of the system_prompt to see which one produces the most syntactically correct SQL.
Cost and Latency: Managing the “GenAI Tax”
Production-grade systems require predictable costs. Langfuse allows us to monitor token usage in real-time.

- Constraint Efficacy: By following our “Minimum Viable Evidence” pattern, we can verify that the agent is staying within a tight token budget (typically < 2k tokens per run).
- Latency Bottlenecks: We can identify if specific tools—like read_source_definitions—are adding unnecessary delay to the MTTR.
The “Merge” Metric: Building the Golden Dataset
The ultimate goal is a high Merge Rate. We use Langfuse scores to track whether the human data engineer actually accepted the AI’s proposal.
- Feedback Loop: When an MR is merged, a GitLab webhook sends a score=1 to the specific Langfuse trace.
- Data Mining: Over time, these “thumbs up” traces become our Golden Dataset—a collection of verified dbt errors and their correct AI-generated fixes, perfect for future fine-tuning or regression testing.
Implementation Note:
from langfuse.decorators import observe @observe() async def dbt_ops_worker(error_log: str): # This single decorator captures all nested tool calls # and PydanticAI structured outputs automatically.
Production Hardening: Turning a Helpful Agent into a Safe System
Guardrails (non-negotiable)
- Repository Scope: The agent can only touch models/—it should never have access to profiles.yml or CI secrets.
- File Type Allowlist: Only .sql files.
- Branch Protections: Never push to main or master.
Evaluation: Proving It Works
| Metric | Target | Purpose |
| MTTR Reduction | > 40% | Measure speed gains. |
| Merge Rate | > 70% | Measure fix quality. |
| Compilation Pass Rate | > 90% | Measure syntax accuracy. |
Extending the System to “Larger Scale”
- Agent Routing: As you scale, use a “Classifier” to determine if the error is a Missing Column, a Schema Drift, or a Syntax Error, routing to specialized prompts for each.
- Shadow Mode: Run the agent in the background for a month, generating fixes but not opening MRs, to build a “Golden Dataset” for evaluation.
By versioning your agent’s traces alongside the actual human-corrected SQL that eventually merged, you create a fine-tuning dataset that can eventually be used to train a smaller, faster model (like GPT-4o-mini, Claude Haiku or an on-premise model) to perform the same task at a fraction of the cost.