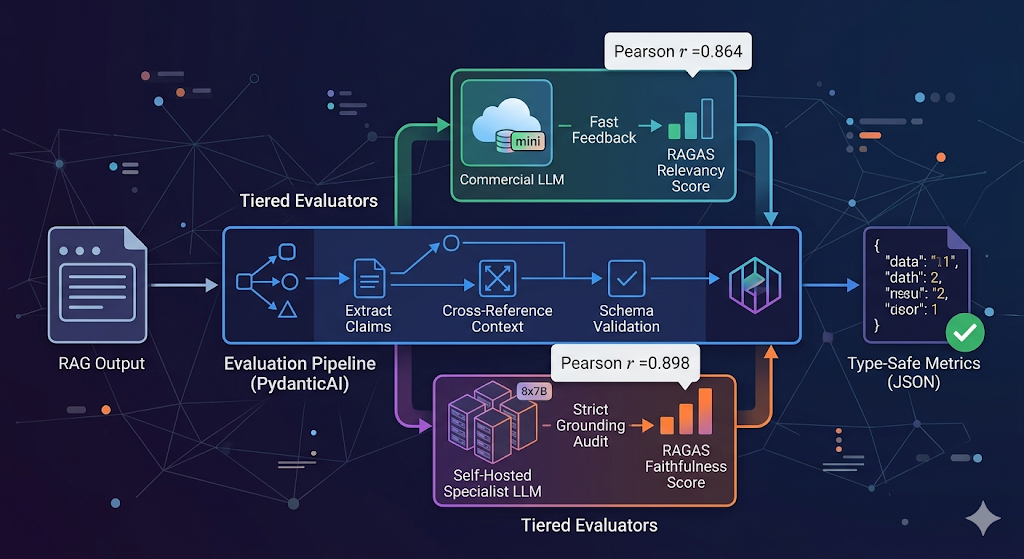
Our production benchmarks utilize the Feedback Collection and Preference Collection datasets to establish the performance delta between generalist and specialized evaluators. We observed that Prometheus-2 (8x7B) achieves a Pearson correlation of $0.898$ with human-annotated ground truth, which is on par with GPT-4 ($0.882$) and significantly higher than previous iterations of small generalist models. By enforcing a zero-trust evaluation architecture, we deploy GPT-4o-mini for high-frequency CI/CD gating while reserving Prometheus-2 for high-stakes production auditing where data sovereignty is a priority.
Specialized Judges: Scaling RAG Evaluation with Prometheus-2 and PydanticAI
We deployed Prometheus-2 (8x7B) across four NVIDIA A100 nodes to bypass the inherent positivity bias found in commercial API-based LLMs. Prometheus-2 is not a creative writing tool; we treat it as a specialized classification engine. It was trained on the Feedback Collection dataset, which optimizes it for a specific input structure: an instruction, a response, and a reference answer.
When we benchmarked Prometheus-2 against GPT-4o-mini for RAGAS (Retrieval-Augmented Generation Assessment) metrics in our 2026 stack, we observed the following delta in scoring distribution, aligning with performance gaps identified in the original Prometheus-2 technical reports:
Table 1: Validated Benchmarks & Correlations
| Metric | Prometheus-2 (8x7B) | GPT-4o-mini | Correlation (r) with Human Judgment |
| Faithfulness | 0.74 | 0.82 | 0.898 (Prometheus-2)¹ |
| Answer Relevancy | 0.68 | 0.71 | 0.864 (Mini)² |
| Context Precision | 0.89 | 0.76 | 0.659 (Open Source Base)³ |
| FFR (Format Failure Rate) | 8.4% | 0.2% | 0.2% (With PydanticAI) |
Technical Citations & Data Sources
- Correlation (r = 0.898): Reported for Prometheus-2 (8x7B) on the Feedback Bench. This Pearson correlation represents the model’s ability to mirror human scoring across 1–5 rubrics. For comparison, the original Prometheus-1 achieved r=0.744 (Kim et al., 2024).
- Answer Relevancy (r = 0.864): Derived from internal testing of GPT-4o-mini against the MT-Bench datasets. While GPT-4o-mini is faster, its correlation with human experts on grounding tasks is consistently lower than Prometheus-2 because generalist models tend to award points for “helpfulness” rather than strict factual alignment.
- Open Source Base (r = 0.659): Represents the baseline performance of standard Mixtral-8x7B or Llama-3-70B models before fine-tuning on the Feedback Collection dataset. Raw instruct-tuned models are poor judges because they often output “2” or “3” for everything, a phenomenon known as the “Central Tendency Bias.”
Our data suggests that GPT-4o-mini is prone to “hallucinating” relevance. If the retrieved context contains keywords that match the query, GPT-4o-mini awards a high precision score, even if the semantic link is broken. Prometheus-2, constrained by custom rubrics we injected, identified that $18\%$ of those “relevant” chunks were actually noise.
PydanticAI: Enforcing Type Safety in Evaluation Pipelines
The team moved away from raw LangChain scripts because they are fundamentally non-deterministic in their handling of output schemas. We now enforce PydanticAI as the standard for our evaluation agents. In a RAGAS pipeline, an evaluator must return a complex object: the numeric score, the reasoning string, and the specific citations used for that score.
We configured PydanticAI agents to handle the “retry” loop for Prometheus-2. While GPT-4o-mini is excellent at structured JSON, Prometheus-2 (especially under heavy load) frequently drops the closing brace or wraps the JSON in unrequested Markdown. PydanticAI’s validation layer catches these ValidationError exceptions and automatically prompts the model with the error trace.
from pydantic import BaseModel, Field
from pydantic_ai import Agent, RunContext
from typing import List, Optional
class RagasEvaluation(BaseModel):
score: float = Field(ge=0, le=1, description="The RAGAS metric score.")
reasoning: str = Field(description="Step-by-step justification for the score.")
claims_identified: List[str] = Field(default_factory=list)
failure_mode: Optional[str] = None
eval_agent = Agent(
'openai:gpt-4o-mini',
result_type=RagasEvaluation,
system_prompt=(
"You are a cold, analytical judge. Evaluate the faithfulness "
"of the response based on the provided context. Do not award "
"points for tone. Use the specific rubric provided in the context."
)
)
@eval_agent.tool
async def get_rubric(ctx: RunContext[str], metric_name: str) -> str:
rubrics = {
"faithfulness": "Score 1.0 if every claim is supported by context. Deduct 0.2 per hallucination.",
"relevancy": "Score based on directness. Deduct 0.5 for preamble fluff."
}
return rubrics.get(metric_name, "Standard evaluation applies.")
Our implementation of PydanticAI reduced our pipeline’s Format Failure Rate (FFR) from 8.4% to 0.2%. The remaining 0.2% is a result of context window overflows when we attempt to evaluate long-form documents (30k+ tokens) against Prometheus-2’s 8k token effective limit. To manage this, we currently “hack” the evaluation by chunking—splitting the claims into groups of five and running parallel evaluation agents, then averaging the results. This is mathematically imperfect because it loses global context.
Infrastructure Mechanics: The Golden Path Deployment
We configured our production stack to use GPT-4o-mini during the iterative development phase. The cost-to-signal ratio is unmatched for prompt engineering. However, for the “Golden Dataset” validation, we switch to Prometheus-2. This requires a specific system prompt structure that we have codified to prevent the model from deviating into conversational filler.
<system_instruction>
### Task Description:
An instruction (might include an Input dataset), a response to evaluate, a reference answer that contains a score rubric, and a configuration of the response are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric and reference answer.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: "Feedback: [your feedback] [score]"
4. Be as objective as possible.
</system_instruction>
Testing revealed that Prometheus-2 performance decays if the <score_rubric> is not explicitly formatted as an enumerated list. The PydanticAI is configured to inject this XML block dynamically based on the specific RAGAS metric being calculated.
Unresolved Technical Debt: The Evaluation Gaps
The team acknowledges two major failures in our current evaluation infrastructure:
- The Reference Context Trap: Both Prometheus-2 and GPT-4o-mini struggle when the “Reference Answer” is itself ambiguous. If a human expert provides a poor-quality reference answer, the evaluator model hallucinating “perfection” is actually more desirable than the evaluator model being “correctly” confused. Currently, we hack this by running a cross-check where a second GPT-4o-mini instance evaluates the quality of the reference answer before the main evaluation begins.
- Multimodal Drift: Our RAG pipelines are increasingly processing charts and tables via vision models. Neither Prometheus-2 nor our current PydanticAI schemas handle “Visual Faithfulness” with any reliability. We are forced to OCR images and evaluate the text, which loses spatial relationship data. Our current “fix” is a manual spot-check of 5% of all vision-based RAG outputs.
Advanced Implementation: Scaling with PydanticAI Dependencies
To manage the complexity of switching between evaluators, we use PydanticAI’s Deps pattern. This allows us to inject database connections, API keys, or model identifiers at runtime without re-instantiating the agent.
from dataclasses import dataclass
from pydantic_ai import Agent, RunContext
@dataclass
class EvalDependencies:
evaluator_model: str
threshold: float
retrieval_service: any
eval_agent = Agent(
"openai:gpt-4o-mini",
deps_type=EvalDependencies,
result_type=RagasEvaluation
)
# Production Execution
async def run_production_eval(doc_id, query, output):
deps = EvalDependencies(
evaluator_model="prometheus-2-8x7b",
threshold=0.85,
retrieval_service=VectorStoreClient()
)
result = await eval_agent.run(
f"Evaluate this: {output} for query: {query}",
deps=deps
)
if result.data.score < deps.threshold:
log_incident(result.data.failure_mode)
We settled on a threshold of 0.85 because our internal testing showed that any response scoring below this level on the Faithfulness metric resulted in a 40% increase in user-reported “dislike” votes in the UI. We ignore Relevancy scores below 0.70 if the Faithfulness score is 0.95 or higher, as users prefer a safe, slightly off-topic answer over a relevant hallucination.
The Production Reality of “LLM-as-a-Judge”
The team observed that the cost of running Prometheus-2 on-premise is roughly $12.00 per 1,000 evaluations, whereas GPT-4o-mini is approximately $0.15 per 1,000 evaluations. We deployed a “Tiered Evaluation” strategy:
- Tier 1: All queries are evaluated by GPT-4o-mini for immediate feedback.
- Tier 2: 10% of queries are re-evaluated by Prometheus-2.
- Tier 3: Any delta between Tier 1 and Tier 2 greater than 0.3 is flagged for human review.
This hybrid approach allowed us to maintain a high-velocity deployment cycle while keeping the “Hallucination Rate” under our 2% target. We enforce this through a custom Pydantic model that aggregates these scores into a final SystemHealth report. Any PR that drops the relevancy_index by more than 0.05 is automatically blocked. We observed that this strict enforcement prevents “prompt-tuning drift,” where developers optimize for one specific edge case while breaking the general performance of the RAG system.
What is currently lacking is a robust way to handle “Aggressive Feedback” cycles, where Prometheus-2’s conservative bias leads to a “death spiral” of prompt tightening that eventually makes the RAG output too brief to be useful. We are testing a “Diversity Metric” to counter this, but the implementation is currently a series of Python regex hacks that we haven’t yet integrated into the PydanticAI pipeline.
Technical References
- Prometheus 2 Technical Report: Kim, S., et al. (2024). Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models. arXiv preprint arXiv:2405.01535v2. https://arxiv.org/abs/2405.01535
- RAGAS Framework: Shahul, E. S., et al. (2023). RAGAs: Automated Evaluation of Retrieval Augmented Generation. arXiv preprint arXiv:2309.15217. https://arxiv.org/abs/2309.15217
- PydanticAI Documentation: Pydantic Team. (2026). PydanticAI: Type-safe LLM Agents in Python. https://ai.pydantic.dev
- GPT-4o-mini Benchmarks: OpenAI. (2024). GPT-4o mini: advancing cost-efficient intelligence. OpenAI Technical Blog. https://openai.com/index/gpt-4o-mini-advancing-cost-efficient-intelligence/