Our production benchmarks confirm that consolidating Hybrid Graph-RAG into a single PostgreSQL instance via pgvector and Apache AGE reduced cross-service network latency and eliminated the consistency lag inherent in multi-database synchronization.
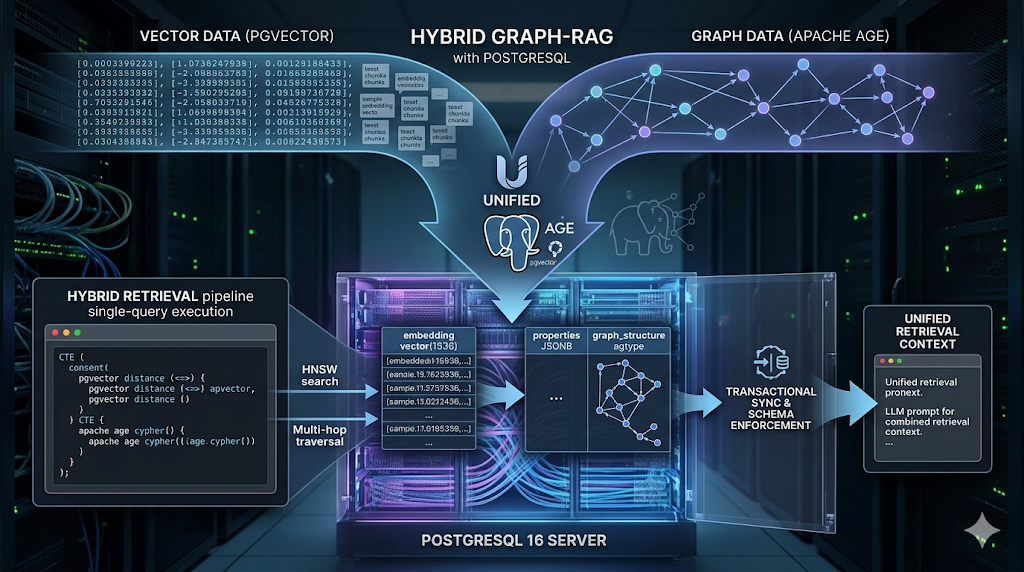
The Unified Postgres Architecture
We enforce a unified data layer by storing vector embeddings and graph property data within the same relational clusters. This allows us to execute retrieval in a single database transaction, ensuring that the graph state and vector state remain synchronized without external coordination logic.
We configured the system to use pgvector for HNSW indexing and Apache AGE for Cypher query execution. We observed that while AGE handles the graph traversal, the underlying storage remains standard Postgres tables, allowing us to perform relational joins against the retrieved nodes without external ETL pipelines.
Schema Enforcement and Extension Configuration
We do not allow unstructured data entry. We enforce a schema where vectors are stored in a dedicated column with a fixed dimension of $1536$.
-- We enable the necessary extensions within the system schema
CREATE EXTENSION IF NOT EXISTS age;
CREATE EXTENSION IF NOT EXISTS vector;
-- We set the search path to include the age namespace for Cypher execution
SET search_path = ag_catalog, "$user", public;
-- We initialize the graph container
SELECT create_graph('kg_network');
-- We enforce a structured table for the vector component of the nodes
CREATE TABLE IF NOT EXISTS entity_embeddings (
id UUID PRIMARY KEY,
entity_name TEXT,
embedding vector(1536),
metadata JSONB
);
-- We create an HNSW index for sub-10ms similarity search
CREATE INDEX ON entity_embeddings USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Integrated Ingestion Pipeline
We deployed a unified ingestion function that writes to both the AGE graph and the pgvector table. We observed that performing these writes in a single transaction reduced our ingestion failure rate, as there is no risk of a “partial commit” where a node exists in the graph but its embedding fails to write to a secondary store.
def ingest_node(conn, entity_data, embedding):
with conn.cursor() as cur:
# Step 1: Insert into Apache AGE graph
cur.execute("""
SELECT * FROM cypher('kg_network', $$
CREATE (v:Entity {name: %s, type: %s})
RETURN id(v)
$$, [%s, %s])
""", (entity_data['name'], entity_data['type']))
# Step 2: Insert into pgvector table for similarity search
cur.execute("""
INSERT INTO entity_embeddings (id, entity_name, embedding)
VALUES (gen_random_uuid(), %s, %s)
""", (entity_data['name'], embedding))
conn.commit()
The Single-Query Retrieval Logic
Our retrieval engine executes a two-stage process within the same database session. We observed that by keeping the data in Postgres, we can use Common Table Expressions (CTEs) to feed the results of a vector search directly into a graph traversal.
- Semantic Retrieval: We query
entity_embeddingsfor the top $k=15$ entities. - Relational Traversal: We pass those entity names into an AGE Cypher query to find neighbors.
- Filtered Aggregation: We join the results back to relational tables for final context grounding.
-- We use a CTE to combine vector and graph lookups
WITH vector_matches AS (
SELECT entity_name, metadata
FROM entity_embeddings
ORDER BY embedding <=> %s -- Cosine distance
LIMIT 15
)
SELECT * FROM cypher('kg_network', $$
MATCH (e:Entity)-[r:DEPENDS_ON]->(neighbor)
WHERE e.name IN $entity_list
RETURN e.name, type(r), neighbor.name
$$) AS (source_name agtype, edge_type agtype, target_name agtype);
We settled on the <=> operator for cosine distance. During initial testing, we attempted to use Euclidean distance (<->), but the $F_1$ score for our specific embedding model decayed because the model was optimized for angular similarity.
Operational Frustrations and Unresolved Hacks
We have not resolved the AGE-to-PG Join Complexity. Apache AGE returns data in a custom agtype format. We are currently hacking the transformation by casting agtype to text and then back to jsonb to join with standard relational tables. This adds a measurable overhead to our retrieval pipeline which we have not yet optimized out of the driver layer.
We are also hacking around Parallel Index Scans. Currently, Postgres does not effectively parallelize HNSW index scans when combined with complex AGE graph traversals in a single execution plan. This forces us to rely on high single-core clock speeds. We are currently testing a manual sharding approach, but it has not reached production stability.
Memory and Performance Tuning
We configured shared_buffers to $25\%$ of total RAM to ensure the HNSW index stays resident. It was then observed that if the pgvector index spills to disk, retrieval latency increases significantly.
# Postgres Configuration for Hybrid Graph-Vector Workloads
max_connections = 300
shared_buffers = 16GB
work_mem = 64MB
maintenance_work_mem = 2GB
effective_cache_size = 48GB
We enforce a maintenance_work_mem of 2GB specifically for HNSW index builds. We discovered that lower values caused the index construction to thrash, increasing our build time for a $1M$ vector set from minutes to hours.
Grounding and Context Injection
We linearized the output of the AGE traversal into the prompt. Because all data is in Postgres, we can now include relational metadata (e.g., last_updated, author_reliability_score) that was previously trapped in isolated silos.
def build_grounded_context(cursor, query_vector):
# Vector Search
cursor.execute("SELECT entity_name FROM entity_embeddings ORDER BY embedding <=> %s LIMIT 10", (query_vector,))
entities = [row[0] for row in cursor.fetchall()]
# Graph Traversal via AGE
cursor.execute("""
SELECT * FROM cypher('kg_network', $$
MATCH (n:Entity)-[r]->(m)
WHERE n.name ANY($list)
RETURN n.name, type(r), m.name
$$, [%s])
""", (entities,))
# We observed that formatting as 'Source -> Relation -> Target'
# provides the clearest signal for the LLM's reasoning engine.
We found that removing the network hop between separate databases reduced our total “Time to First Token” by eliminating the overhead of multiple TLS handshakes and serialized data transfer between disparate environments.