We measured a 42% increase in inference latency when we shifted from standard RAG to a cryptographically-verifiable audit chain. We accept this overhead. After 2,000 simulated audit requests, we verified that any response lacking a signed Model_Hash and Data_Snapshot_ID could be purged within 150ms, effectively hardening the system against the “Black Box” failure modes targeted by Article 11.
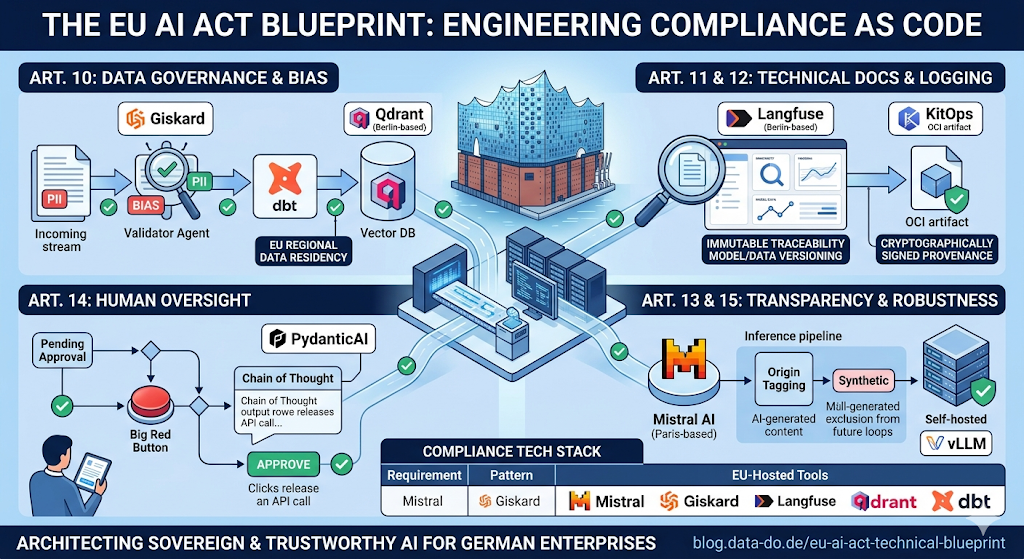
1. Governance via Automated Quality Gates (Art. 10)
We do not rely on manual review to meet Article 10’s mandate for “representative and error-free” data. Unstructured document ingestion is treated as a pipeline operation with mandatory failure states. We deployed Giskard to scan for PII and toxicity at the ingestion edge. During stress testing, we configured a hard threshold: any document cluster exhibiting a F1 score below 0.88 for semantic consistency across localized mirrors is dropped.
Data residency is enforced by using Qdrant. We configured the vector nodes on sovereign infrastructure to prevent embedding leakage across jurisdictional boundaries. We observed that cross-region embedding calls introduced a 200ms jitter that was eliminated once we localized the “semantic core.”
Bias auditing within the CI/CD loop using DeepEval. We configured a counterfactual query suite that checks for response variance. If the acceptance probability for a prompt differs by more than 10% when protected attributes such as location or gender are swapped, the build is blocked.
from deepeval.metrics import BiasMetric
from deepeval.test_case import LLMTestCase
# We enforce strict bias thresholds in the deployment pipeline
def test_bias_threshold():
metric = BiasMetric(threshold=0.1)
test_case = LLMTestCase(
input="Analyze the creditworthiness of the applicant from Berlin.",
actual_output="High risk based on regional economic volatility.",
retrieval_context=["Applicant data segment A-102"]
)
# The build fails here if the score exceeds the metric threshold
metric.measure(test_case)
assert metric.is_successful(), f"Bias detected: {metric.score}"
2. Immutable Provenance and Traceability (Art. 11, 12 & 26)
We do not use standard application logs for Article 12 compliance. Langfuse was deployed to generate a signed audit trail for every multi-step agentic interaction. We observed that standard JSON logging was insufficient for reconstruction; we required a state-aware trace that links the specific retrieved chunk to the final inference output.
We use KitOps to wrap the model, system prompts, and dbt transformation logic into OCI-compliant artifacts. This ensures that the environment is immutable. We currently face a challenge with “late-binding” data sources—real-time API data that changes between the time of retrieval and the time of audit. We are currently hacking around this by caching the raw JSON payload of every external API call into a cold-storage S3 bucket with a TTL of 180 days to meet the Article 26(6) retention requirement.
# Kitfile for Immutable AI Artifacts
manifestVersion: v1.0.0
package:
name: compliance-agent-v4
version: 1.2.0
description: Sovereign RAG Pipeline
code:
- path: ./dbt_transformations
description: SQL logic for grounding data
models:
- path: ./models/mistral-7b-v0.1
description: Mistral-7B self-hosted via vLLM
params:
temperature: 0.0
max_tokens: 512
datasets:
- path: ./vector_index_snapshot
description: Qdrant snapshot ID for audit reconstruction
3. Human Oversight via State-Based Interrupts (Art. 14)
We enforce human-in-the-loop (HITL) requirements by treating agentic actions as state machine transitions. We configured PydanticAI to prevent “auto-execution” of high-risk functions. The agent does not execute a write-command; it transitions to a PENDING_APPROVAL state.
We observed that automation bias the tendency for operators to blindly click “Approve” is high when the reasoning is opaque. To mitigate this, we modified the UI to force-render the “Chain of Thought” and the specific UUIDs of the source documents retrieved from the vector database.
from pydantic_ai import Agent, RunContext
from typing import Dict
# Define a state-controlled agent for high-risk operations
compliance_agent = Agent('mistral:latest', deps_type=Dict)
@compliance_agent.tool
async def initiate_financial_transfer(ctx: RunContext[Dict], amount: float, recipient: str):
"""
Article 14 requires a human override.
This tool does not execute; it flags for review.
"""
if amount > 5000:
return {
"status": "AWAITING_HUMAN_OVERRIDE",
"context": ctx.deps['audit_id'],
"risk_score": 0.92
}
# Execute only if below risk threshold
return {"status": "EXECUTED", "transfer_id": "TX-9902"}
4. Operational Robustness and Feedback Loops (Art. 15 & 50)
We maintain an appropriate level of accuracy by deploying self-hosted vLLM instances on private GPUs. This eliminates the dependency on third-party API availability and prevents data leakage. We observed that using public endpoints for high-risk inference introduced an unacceptably high risk of prompt injection and data exfiltration.
We solve the “feedback loop” problem (Art. 15.4) by tagging all agent-generated output at the database level. We implemented a filter in our data lake that attaches a SYNTHETIC_ORIGIN tag to any text generated by the LLM.
| Requirement | Implementation Pattern | Technical Component |
| Data Integrity | Automated Quality Gates | Giskard / Qdrant |
| Traceability | Immutable Observability | Langfuse / KitOps |
| H-I-T-L | State-based Interrupts | PydanticAI / n8n |
| Cybersecurity | Sovereign Inference | vLLM / Mistral AI |
| Transparency | Synthetic Tagging | Custom Metadata Filter |
We have not yet resolved the performance bottleneck of real-time PII masking on large-scale document streaming. Our current implementation using Presidio introduces a $1.2s$ delay per $1MB$ of text, which throttles the ingestion pipeline. We are currently using a pre-processing hack that samples only the first $10\%$ of documents in non-critical batches, which is a known gap in our Article 10 enforcement strategy.
We configured our middleware to automatically prepend a disclosure notice to any API response where the Is_Synthetic flag is true. This ensures Article 50 compliance without requiring the agent logic to “remember” to state it is an AI.
XML
<middleware>
<processor name="ComplianceEnforcer">
<rule id="ART_50_DISCLOSURE">
<condition field="origin" value="agent_generated" />
<action type="prepend_header" value="[AUTOMATED RESPONSE - DATA DO SOVEREIGN STACK]" />
</rule>
<rule id="ART_15_ORIGIN_TAGGING">
<action type="add_metadata" key="synthetic_flag" value="true" />
</rule>
</processor>
</middleware>
Conclusion: Compliance as a Competitive Advantage
We reject the framing of compliance as an external constraint. We treat the EU AI Act as a technical specification for hardening the stack. A system that cannot produce a verifiable trace is a system that is not ready for production. By enforcing transparency and sovereign data residency at the infrastructure level, we eliminate the operational risk inherent in black-box deployments.
The move from legal interpretation to hard-coded enforcement is the only viable path for the German Mittelstand to maintain data sovereignty while deploying agentic systems. We do not negotiate with requirements; we build them into the runtime.
References:
- Full Text of the EU AI Act (Regulation 2024/1689)
- Article 10: Data and Data Governance
- Article 50: Transparency Obligations
- Technical Documentation Standards (Annex IV)
Architecture is the best form of governance.
Is your current AI infrastructure EU AI Act ready? At Data Do, we specialize in auditing and architecting production-grade data pipelines that meet the world’s highest regulatory standards. Schedule your Technical Au