Apache Zeppelin is pretty usefull for interactive programming using the web browser. It even comes with its own installation of Apache Spark. For further information you can check my earlier post.
But the real power in using Spark with Zeppelin lies in its easy way to connect it to your existing Spark cluster using YARN. The following steps are necessary:
- Copy your Hadoop configuration files to your Zeppelin installation under $ZEPPELIN_HOME/conf
- Restart your Zeppelin Notebook
- Insert the value “yarn-client” into the field master in the spark interpreter, as shown in the picture below.
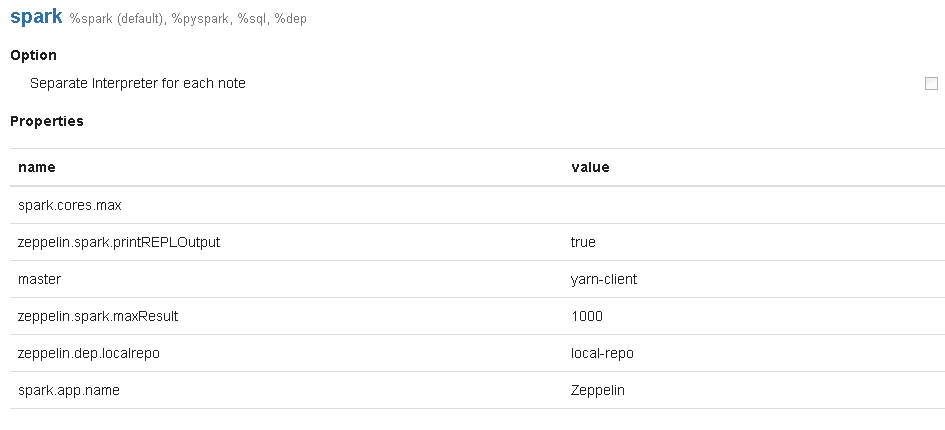
After these steps you can use your notebooks with spark running on a yarn cluster. So you can make use of all the resources in the queue you assigned spark on you cluster.
Leave a Reply