As we look toward the next phase of industrial AI, the German Mittelstand is poised to move beyond “AI as a Chatbot” and toward the LLM-as-a-Compiler pattern. This represents a fundamental shift from “AI as a Librarian” to a “Deterministic Data Engineer.”
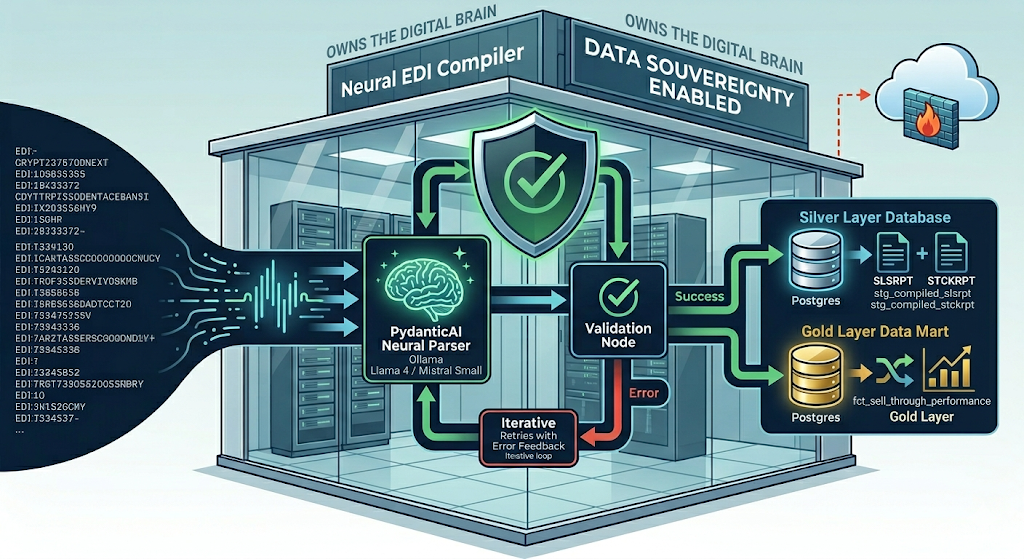
The following architecture serves as a primary example of how this compiler pattern can be leveraged: transforming the notoriously cryptic world of EDI Sell-Through Reporting into a live, high-precision dashboard by using PydanticAI for segment parsing and LangGraph for workflow orchestration.
The Inputs: Raw EDIFACT Payloads
Our pipeline starts with the “Source Code” of global trade: the EDI message. These are non-human-readable segments that traditionally require rigid, manual mapping.
Example: Raw SLSRPT (Sales Report) BGM+12+SALES_2026_WK12+9'DTM+137:20260328:102'NAD+MS+STORE_HAMBURG'LIN+1++4001234567890:EN'QTY+153:45'MOA+128:1125.00:EUR'
Example: Raw STCKRPT (Stock Report) BGM+35+STOCK_2026_WK12+9'DTM+137:20260328:102'NAD+WH+WH_CENTRAL_DE'LIN+1++4001234567890:EN'QTY+145:500'LOC+1+BIN_A12'
The Neural Compilers: PydanticAI Agents
To truly understand the Neural Compiler pattern, we must move away from the idea of “Prompting” and toward the idea of “Type-Safe Extraction.” In this stage, the LLM is not generating text; it is performing a high-dimensional mapping from a raw string to a strictly defined Python object.
By using PydanticAI, we create a contract between the LLM and the database. If the LLM produces a field that doesn’t match the schema (e.g., a string where an integer is expected), PydanticAI intercepts the error and can even re-prompt the model to fix its own mistake.
The Schema as the “Binary Target”
The first step in a Neural Compiler is defining the Target Object. For STCKRPT and SLSRPT, we use Pydantic models to enforce business rules directly at the point of ingestion.
- Constraint Enforcement: Using
Field(..., gt=0)ensures that the LLM cannot hallucinate a “negative” sale. - Data Normalization: We use
@field_validatorto handle the cryptic EDI date formats (e.g.,102forYYYYMMDD) before the data ever touches the database.
from pydantic import BaseModel, Field, field_validator
from datetime import datetime
class StockItem(BaseModel):
sku: str = Field(..., description="The EAN or internal SKU found in the LIN segment")
on_hand_qty: int = Field(..., ge=0, description="The inventory count from the QTY+145 segment")
class StockReport(BaseModel):
warehouse_id: str = Field(..., description="The storage location ID from the NAD+WH segment")
report_date: datetime
inventory: list[StockItem]
@field_validator("report_date", mode="before")
@classmethod
def validate_edi_date(cls, v: str) -> datetime:
# Automatically converts '20260328' into a Python datetime object
return datetime.strptime(v, "%Y%m%d")
The Agent as the “Neural Logic Gate”
The PydanticAI Agent acts as the compiler’s execution engine. It combines the System Prompt (the instructions) with the Result Type (the schema).
- System Prompt (The Grammar): This tells the LLM specifically which EDI segments matter. Instead of “Read this EDI,” we say: “Focus on the LIN+1 segment for the SKU and the subsequent QTY+145 segment for the inventory balance.”
- Structured Output: Because we pass
result_type=StockReportto the agent, the LLM is physically constrained to output JSON that matches that exact structure.
from pydantic_ai import Agent
# Define the Compiler for Stock Reports
stock_compiler = Agent(
'ollama:llama4',
result_type=StockReport,
system_prompt=(
"You are a technical EDIFACT-to-JSON compiler specializing in INVRPT messages. "
"1. Identify the NAD+WH segment for the warehouse_id. "
"2. Identify the DTM+137 segment for the report_date. "
"3. Loop through every LIN segment to extract the SKU and its QTY+145."
)
)
3. The “Fail-Fast” Mechanism
In a traditional RAG setup, if an LLM gets confused, it might apologize or make up a plausible answer. In the Neural Compiler pattern:
- The LLM attempts to map the EDI string to the
StockReportmodel. - If it returns a SKU that is a number instead of a string, or a negative quantity, PydanticAI raises a ValidationError.
- The LangGraph orchestrator (the next step in the stack) catches this and decides whether to retry with the error log or flag the message for manual review.
This creates a deterministic bridge over a probabilistic gap. We use the LLM for its “eyes” (understanding the messy EDI) but use Pydantic for its “brain” (ensuring the data is 100% correct).
3. The Orchestrator: LangGraph Multi-Step Flow
A production-grade pipeline must manage state and dependencies. We use LangGraph to ensure the Sell-Through transformation only triggers once both the Sales and Stock data have been successfully compiled and validated.
Detailed Flow Architecture:
- Ingest Node: Receives the raw EDI strings for SLSRPT and STCKRPT.
- Parallel Compilation Node: Triggers both PydanticAI agents. If one fails, the graph catches the exception.
- Validation Node: Checks the
result_typefor integrity. - Database Load Node: Upserts the parsed data into the “Silver” layer of a PostgreSQL database.
- dbt Transformation Node: Executes a shell command to trigger the dbt models for analytics.
graph TD
%% Define Nodes with manual line breaks
Ingest[Ingest Node:<br/>Receive Raw EDI Strings]
ParallelComp{Parallel<br/>Compilation}
SalesAgent[Sales Agent:<br/>Neural SLSRPT Compiler]
StockAgent[Stock Agent:<br/>Neural STCKRPT Compiler]
Validation{Validation Node:<br/>Check result_type}
DBLoad[Database Load Node:<br/>PostgreSQL Silver Layer]
DBTNode[dbt Transformation:<br/>Calculate Sell-Through]
Alert[Alerting Node:<br/>Slack/Logfire Failure]
Success[END:<br/>Analytics Ready]
%% Main Flow
Ingest --> ParallelComp
%% Parallel Path
ParallelComp --> SalesAgent
ParallelComp --> StockAgent
%% Validation Step
SalesAgent --> Validation
StockAgent --> Validation
%% Logic Branching
Validation -- Valid Data --> DBLoad
Validation -- Invalid/Error --> Alert
%% Success Path
DBLoad --> DBTNode
DBTNode --> Success
%% Error Catching
DBTNode -- Build Error --> Alert
%% Styling for Visual Hierarchy
style Ingest fill:#e1f5fe,stroke:#01579b
style ParallelComp fill:#fff9c4,stroke:#fbc02d
style Validation fill:#fff9c4,stroke:#fbc02d
style DBLoad fill:#e8f5e9,stroke:#2e7d32
style DBTNode fill:#e8f5e9,stroke:#2e7d32
style Alert fill:#ffcdd2,stroke:#c62828
style Success fill:#c8e6c9,stroke:#1b5e20
from langgraph.graph import StateGraph, END
from typing import TypedDict, List
class PipelineState(TypedDict):
raw_sales: str
raw_stock: str
parsed_sales: Optional[SalesReport]
parsed_stock: Optional[StockReport]
errors: List[str]
def compilation_node(state: PipelineState):
try:
# Simultaneous neural compilation
s_res = sales_agent.run_sync(state["raw_sales"])
t_res = stock_agent.run_sync(state["raw_stock"])
return {"parsed_sales": s_res.data, "parsed_stock": t_res.data}
except Exception as e:
return {"errors": [str(e)]}
workflow = StateGraph(PipelineState)
workflow.add_node("compile", compilation_node)
workflow.add_node("dbt_transform", run_dbt_command)
workflow.add_edge("compile", "dbt_transform")
workflow.set_entry_point("compile")
4. The Transformation: dbt Sell-Through Mart
Once the neural compiler has pushed deterministic data into PostgreSQL, dbt takes over to provide the final business intelligence layer.
-- marts/fct_sell_through_performance.sql
WITH sales AS (
SELECT sku, store_id, SUM(units_sold) as total_sold
FROM {{ ref('stg_compiled_slsrpt') }}
GROUP BY 1, 2
),
stock AS (
SELECT sku, store_id, on_hand_qty as current_stock
FROM {{ ref('stg_compiled_stckrpt') }}
WHERE report_date = CURRENT_DATE
)
SELECT
s.sku,
s.store_id,
s.total_sold,
st.current_stock,
-- Sell-Through Rate = Units Sold / (Units Sold + Available Stock)
ROUND((s.total_sold::float / NULLIF(s.total_sold + st.current_stock, 0)) * 100, 2) as sell_through_pct
FROM sales s
JOIN stock st ON s.sku = st.sku AND s.store_id = st.store_id
5. Conclusion: The Strategic Blueprint
This EDI case study is just one example of the broader shift toward LLM-as-a-Compiler. By moving from probabilistic chatting to deterministic data engineering, firms gain:
Vision: The future of the Mittelstand lies in owning the “Digital Brain” turning messy operational data into a strategic asset.ine?
Integrity: PydanticAI ensures only “valid” data enters the stack.
Resilience: LangGraph manages the complexities of real-world failures.
Why Partner With Us?
We don’t start from scratch. We deploy our audited reference architecture directly into your infrastructure, customized for your specific document types:
- Accelerated Deployment: Skip 6+ months of R&D with our pre-built Docling, Pydantic AI, and Langfuse integrations.
- Total Data Sovereignty: Our “Local-First” Docker stack ensures your sensitive data never leaves your firewall.
- Guaranteed Precision: We move beyond naive similarity search to hybrid, agent-enriched retrieval that matches human-level accuracy.
Schedule a Technical Strategy Session
If your current RAG implementation is struggling with complex layouts, losing context in chunks, or failing to scale on-premise, let’s talk.
We will walk you through a live demonstration of the blueprint using your own document samples and discuss how to integrate this architecture into your existing stack.
Book a RAG Strategy Consultation
Direct access to our lead architects. No sales fluff, just engineering.