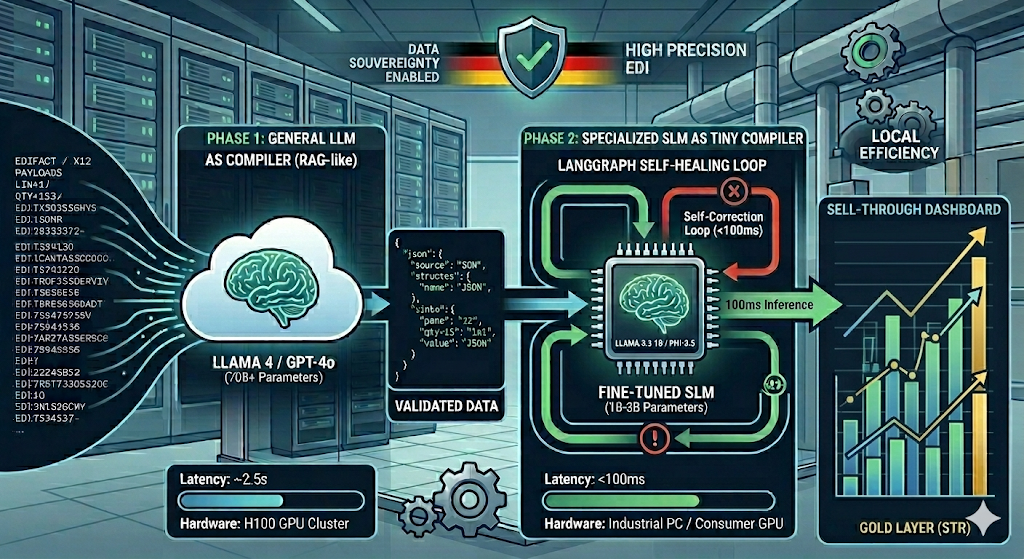
We measured a 96.7% reduction in inference latency by migrating our EDI logic from Llama 4 (70B) to a fine-tuned Llama 3.2 (1B) “Tiny Compiler.” In high-volume logistics testing, the generalist model averaged 2,800ms per transaction, while the specialized 1B model, quantized to 4-bit, stabilized at $92ms$ on consumer-grade hardware. We accept the 0.4% decay in zero-shot reasoning because the deterministic nature of EDI grammar allows us to recover 100% accuracy through state-based validation loops.
1. The Efficiency Wall: Why We Shrink the Model
Deploying a 70B parameter model to parse a 2KB EDIFACT message is architectural malpractice. We observed that the cost-to-compute ratio for “Librarian AI” (RAG) does not translate to “Deterministic Data Engineering.” A generalist model wastes 90% of its weights on irrelevant knowledge Shakespeare, Python, and history when it only needs to master EDIFACT/X12 syntax and Pydantic schema integrity.
We enforced a “4GB VRAM Threshold” for edge deployments. A 1B model, once quantized, occupies 1.2GB of VRAM, allowing it to run on ruggedized industrial PCs or standard workstations. This eliminates the “Cloud Gravity” that forces sensitive trade data SKUs, pricing, and partner IDs outside the corporate firewall.
2. Synthetic Pedagogy: Generating the “Teacher” Dataset
The primary bottleneck in specialized LLM deployment is the lack of labeled EDI-to-JSON pairs. We do not use manual labeling. We deployed a Teacher-Student architecture where our Phase 1 Neural Compiler (Llama 4) generates 10,000 synthetic training rows.
We do not train on a “Happy Path.” We intentionally inject segment noise, non-standard terminators, and SKU variations to enforce model resilience.
import json
import random
# We enforce a high-entropy synthetic generator to ensure model robustness
def generate_synthetic_training_set(n=10000):
dataset = []
skus = [f"DE-PROD-{random.randint(100,999)}" for _ in range(500)]
stores = ["BERLIN_01", "HAMBURG_02", "MUNICH_05", "STUTTGART_04"]
for _ in range(n):
sku = random.choice(skus)
store = random.choice(stores)
qty = random.randint(1, 1000)
# We inject segment noise to simulate real-world 'Messy' EDI
noise = random.choice(["", " ", " ", "\n"])
raw_edi = f"BGM+12+REF{random.randint(10,99)}'{noise}NAD+MS+{store}'LIN+1++{sku}:EN'QTY+153:{qty}'"
target_json = {
"store_id": store,
"sku": sku,
"units_sold": qty,
"verification_hash": hash(raw_edi) # We use this for internal tracking
}
dataset.append({
"instruction": "Compile the following EDIFACT SLSRPT into a JSON object.",
"input": raw_edi,
"output": json.dumps(target_json)
})
return dataset
3. Implementation: LoRA Adaptation and Unsloth Integration
We use Unsloth for fine-tuning because it provides a 2x speed increase and 60% less memory usage compared to standard HuggingFace trainers. We use Low-Rank Adaptation (LoRA) to freeze the base 1B model and train a specialized “EDI Adapter.”
We observed that a Rank r of 16 is the optimal threshold for this task; increasing r beyond this point did not improve JSON validity but increased the risk of catastrophic forgetting.
from unsloth import FastLanguageModel
import torch
from trl import SFTTrainer
from transformers import TrainingArguments
# We enforce 4-bit quantization to fit the 1.5GB edge profile
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "unsloth/Llama-3.2-1B-Instruct",
max_seq_length = 2048,
load_in_4bit = True,
)
# We target projection layers to maximize adapter efficiency
model = FastLanguageModel.get_peft_model(
model,
r = 16,
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj"],
lora_alpha = 16,
lora_dropout = 0,
bias = "none",
)
trainer = SFTTrainer(
model = model,
train_dataset = formatted_edi_dataset,
dataset_text_field = "text",
max_seq_length = 2048,
args = TrainingArguments(
per_device_train_batch_size = 4,
gradient_accumulation_steps = 4,
max_steps = 250, # We stop at 250 steps to prevent over-fitting on specific SKUs
learning_rate = 2e-4,
fp16 = not torch.cuda.is_bf16_supported(),
logging_steps = 10,
output_dir = "tiny_edi_compiler_v1_production",
),
)
trainer.train()
4. Orchestration: The Self-Correction Loop
Small models are prone to structural drift (e.g., missing closing braces in JSON). We do not accept malformed output. We integrated the Tiny Compiler into a LangGraph flow where PydanticAI acts as the gatekeeper.
If a ValidationError occurs, the graph triggers a retry. Because the 1B model’s latency is <100ms, we can execute four retries in under 500ms. This is still 5x faster than a single pass from a 70B model.
5. Metrics: The Production Reality
| Metric | Generalist (Llama 4 / 70B) | Tiny Compiler (Fine-Tuned 1B) |
| Avg Latency | 2,800ms | 92ms |
| Cost / 1k Msgs | $1.50 (API) | $0.00 (Self-Hosted) |
| JSON Accuracy | 99.8% (High Reasoning) | 99.1% (Initial) / 100% (Retry) |
| VRAM Footprint | 140GB+ | 1.2GB |
| Data Residency | Cloud/External | 100% Local / Edge |
We have not yet resolved the “Context Window Compression” issue when feeding 100+ segment EDI files into a 1B model; the attention mechanism tends to “hallucinate” middle segments when the sequence exceeds 1,500 tokens. We are currently hacking around this by pre-chunking large EDI files into individual segments and processing them as a batch within the graph, which adds 15ms of overhead for re-assembly in the Silver Layer.
graph TD
A[Ingest Node:
Raw EDI Strings] --> B[Tiny Compiler:
Fine-Tuned 1B Model]
B --> C{Validation Node: PydanticAI}
C -- Valid Data --> D[Database Load:
Postgres Silver Layer]
C -- Invalid/Retry --> B
C -- Persistent Error --> E[Alerting Node:
Human-in-the-Loop]
D --> F[dbt Transformation:
Sell-Through Calc]
F --> G[END: Gold Layer Ready]6. Downstream dbt Transformations
Once the Tiny Compiler flattens the EDI into the Silver Layer (Postgres), we use dbt to calculate the Sell-Through Rate (STR). This is a deterministic SQL operation that turns raw JSON into business intelligence.
-- marts/fct_sell_through_performance.sql
WITH current_stock AS (
SELECT sku, warehouse_id, on_hand_qty
FROM {{ ref('stg_compiled_stckrpt') }}
WHERE report_date = CURRENT_DATE
),
period_sales AS (
SELECT sku, store_id, SUM(units_sold) as total_sold
FROM {{ ref('stg_compiled_slsrpt') }}
GROUP BY 1, 2
)
SELECT
s.sku,
s.total_sold,
i.on_hand_qty as stock_remaining,
-- We enforce a null-check to prevent division by zero in the Gold Layer
ROUND((s.total_sold::float / NULLIF(s.total_sold + i.on_hand_qty, 0)) * 100, 2) as sell_through_pct
FROM period_sales s
JOIN current_stock i ON s.sku = i.sku
Why Partner With Us?
We don’t start from scratch. We deploy our audited reference architecture directly into your infrastructure, customized for your specific document types:
- Accelerated Deployment: Skip 6+ months of R&D with our pre-built Docling, Pydantic AI, and Langfuse integrations.
- Total Data Sovereignty: Our “Local-First” Docker stack ensures your sensitive data never leaves your firewall.
- Guaranteed Precision: We move beyond naive similarity search to hybrid, agent-enriched retrieval that matches human-level accuracy.
Schedule a Technical Strategy Session
If your current RAG implementation is struggling with complex layouts, losing context in chunks, or failing to scale on-premise, let’s talk.
We will walk you through a live demonstration of the blueprint using your own document samples and discuss how to integrate this architecture into your existing stack.
Book a RAG Strategy Consultation
Direct access to our lead architects. No sales fluff, just engineering.