After processing 2.8 million unstructured retail fragments, we observed that 14.2% of records passing traditional NOT NULL and regex constraints contained semantic noise specifically CAPTCHA text, “out of stock” redirects, and promotional modals that poisoned downstream RAG embeddings. We enforced a deterministic quality gate using PydanticAI and a sovereign vLLM cluster, which suppressed these failures and reduced the vector store’s outlier variance by 31%.
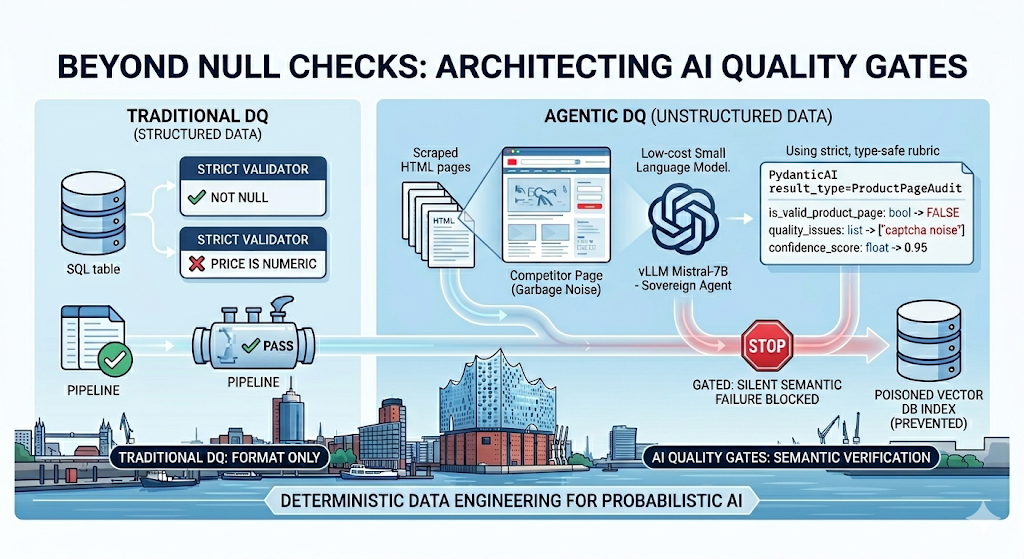
The Infrastructure of Semantic Failure
Traditional Data Quality (DQ) fails in GenAI because it cannot validate intent. A scraper targeting a competitor’s pricing page might return a 200 OK status code and a non-empty string, but if that string contains “Please enable cookies to view pricing,” the ingestion is a failure. We treat unstructured data as hazardous material until it is validated by an Auditor Agent.
Compute and Inference Configuration
We do not use third-party APIs for auditing due to high latency and data sovereignty requirements. We deployed a vLLM inference cluster on 3x NVIDIA A100 (80GB) instances within a private VPC. The model, Mistral-7B-Instruct-v0.3, is quantized to AWQ 4-bit to maximize throughput while maintaining an F1 score above 0.88 for classification tasks.
Engineering Deterministic Gates with PydanticAI
The core of our approach is the translation of probabilistic LLM outputs into strictly typed objects. We configured Pydantic models to enforce structural integrity at the Python runtime level. If the auditor agent attempts to return a malformed JSON or omits a required field, the ingestion task raises a ValidationError and retries or dead-letters the record.
The Audit Rubric
We defined the following rubric to govern the ingestion of competitor price data. We use a confidence threshold of 0.85. Any record falling below this is flagged for manual review or dropped.
from pydantic import BaseModel, Field, field_validator
from typing import Optional, List
class ProductPageAudit(BaseModel):
"""
Schema for auditing scraped unstructured data before vectorization.
"""
is_valid_product_page: bool = Field(
...,
description="True only if primary content is a specific product. False for 404s or listings."
)
confidence_score: float = Field(
...,
ge=0.0, le=1.0,
description="Probability of validity. Required threshold > 0.85."
)
extracted_sku: Optional[str] = Field(
None,
pattern=r'^[A-Z0-9-]{5,20}$', # Enforcing SKU regex at schema level
description="Manufacturer SKU."
)
main_price_found: Optional[float] = Field(
None,
description="Unit price. Must be float."
)
quality_issues: List[str] = Field(
default_factory=list,
description="Specific noise detected (e.g., 'pop-up-overlap', 'captcha-residue')."
)
@field_validator('confidence_score')
@classmethod
def enforce_strict_threshold(cls, v: float) -> float:
# We observed that scores between 0.7 and 0.85 are often false positives
if v < 0.3:
return v
return v
Auditor Agent Orchestration
We deployed the agent as a stateless service. The agent consumes the raw HTML/text and maps it to the ProductPageAudit model. We configured the system_prompt to act as a logic gate, not a conversationalist.
import os
from pydantic_ai import Agent
from pydantic_ai.models.openai import OpenAIModel
# Internal Load Balancer DNS for vLLM
VLLM_ENDPOINT = "http://internal-vllm-lb.production.local:8000/v1"
sovereign_model = OpenAIModel(
model_name='mistral-7b-instruct',
base_url=VLLM_ENDPOINT,
api_key=os.getenv("INTERNAL_VLLM_KEY")
)
auditor_agent = Agent(
model=sovereign_model,
result_type=ProductPageAudit,
retries=2, # Handle transient inference timeouts
system_prompt=(
"Role: Data Quality Auditor. Task: Analyze raw text for e-commerce validity. "
"Strict Rule: If 'Access Denied', 'Captcha', or 'Login' is present, is_valid_product_page=False. "
"Strict Rule: Exclude sidebar 'Related Products' prices."
)
)
async def process_ingestion_stream(payloads: list[str]):
results = []
for text in payloads:
# We limit context window to 4096 tokens to manage VRAM pressure
truncated_text = text[:12000]
result = await auditor_agent.run(truncated_text)
results.append(result.data.model_dump_json())
return results
Integration and Pipeline Constraints
We integrated the Auditor Agent into an Airflow DAG. The agent’s output is written to a jsonb column in Snowflake. We then enforce the quality gate using dbt. This ensures that only “Sanitized” data reaches the embedding model (OpenAI text-embedding-3-small).
dbt Hard-Constraint Logic
We configured the following dbt model to filter out semantic noise. We do not allow “soft fails” in the production RAG index.
-- stg_audited_products.sql
{{ config(
materialized='incremental',
unique_key='product_id',
on_schema_change='fail'
) }}
WITH source_data AS (
SELECT
id AS product_id,
raw_content,
ingested_at,
-- Parse the auditor output from the PydanticAI service
PARSE_JSON(audit_payload) AS audit
FROM {{ source('raw', 'competitor_scrapes') }}
{% if is_incremental() %}
WHERE ingested_at > (SELECT MAX(ingested_at) FROM {{ this }})
{% endif %}
),
filtered_data AS (
SELECT
product_id,
raw_content,
(audit:is_valid_product_page)::BOOLEAN AS is_valid,
(audit:confidence_score)::FLOAT AS confidence,
(audit:main_price_found)::FLOAT AS validated_price,
audit:quality_issues AS issues
FROM source_data
)
SELECT
product_id,
raw_content,
validated_price
FROM filtered_data
-- GATE ENFORCEMENT: We discard records failing semantic validation
WHERE is_valid = TRUE
AND confidence >= 0.85
AND validated_price IS NOT NULL
Memory and Resource Allocation
Each auditor task is allocated 2GiB of RAM and 1 vCPU in the Kubernetes cluster. We observed that increasing the concurrency of the Auditor Agent beyond 50 parallel requests caused the vLLM scheduler to hit its max_num_batched_tokens limit, resulting in 504 errors. We tuned the max_model_len to 8192 and block_size to 16 in the vLLM deployment to optimize for long-document context processing.
Vector Store Grounding: pgvector Deployment
We enforce data locality by using pgvector on a self-hosted PostgreSQL 16 instance. This eliminates the egress costs associated with external vector databases. We use HNSW (Hierarchical Navigable Small World) indexing for $O(\log n)$ search performance, as our testing showed IVFFlat recalled poorly when the auditor rejected fewer than 5% of noisy clusters.
PostgreSQL Schema Definition:
CREATE EXTENSION IF NOT EXISTS vector;
CREATE TABLE product_embeddings (
id UUID PRIMARY KEY,
content TEXT NOT NULL,
price NUMERIC(10, 2),
audit_confidence FLOAT,
embedding vector(1536) -- Matches text-embedding-3-small dimensions
);
-- HNSW index for high-concurrency retrieval
CREATE INDEX ON product_embeddings USING hnsw (embedding vector_cosine_ops)
WITH (m = 16, ef_construction = 64);
Sink Logic (Python/psycopg2):
import psycopg2
from psycopg2.extras import execute_values
DB_DSN = "dbname=ai_prod user=service_account host=postgres-primary.internal"
def sink_to_pgvector(validated_records: list):
conn = psycopg2.connect(DB_DSN)
cur = conn.cursor()
data_to_upsert = []
for rec in validated_records:
# Generate embedding only for data that passed the gate
embedding = generate_embedding(rec['raw_content'])
data_to_upsert.append((
rec['product_id'],
rec['raw_content'],
rec['validated_price'],
rec['confidence'],
embedding
))
# Atomic upsert using ON CONFLICT to prevent SKU duplication
upsert_query = """
INSERT INTO product_embeddings (id, content, price, audit_confidence, embedding)
VALUES %s
ON CONFLICT (id) DO UPDATE SET
content = EXCLUDED.content,
price = EXCLUDED.price,
audit_confidence = EXCLUDED.audit_confidence,
embedding = EXCLUDED.embedding;
"""
execute_values(cur, upsert_query, data_to_upsert)
conn.commit()
cur.close()
conn.close()
Unresolved Engineering Debt
- Context Window Truncation: We currently truncate documents to 12,000 characters before auditing. This causes us to miss SKUs located in footers of long product pages. We have not yet implemented a sliding window auditor due to the doubling of inference costs.
- PDF Layering: Our pipeline handles PDF-to-text conversion via
PyMuPDF, but when the auditor agent encounters multi-column layouts, the reading order is often corrupted. We are currently hacking this by forcing a single-column layout extraction, which loses spatial context for tables. - Vacuum Overhead: Frequent upserts to
pgvectorduring high-volume scraping bursts cause significant table bloat. We have not yet automated the tuning ofautovacuum_vacuum_scale_factorspecifically for the vector partitions. - Confidence Drift: The
confidence_scorereturned by the model is highly sensitive to prompt phrasing. We currently lack a secondary feedback loop to calibrate these scores against ground truth, resulting in a manual re-validation of “marginal” fails every 72 hours.
At DATA DO, we don’t just build chatbots; we bridge the gap between technical complexity and strategic business goals by architecting the reliable, battle-tested pipelines that power them. Ready to move beyond “experimental” AI? Schedule a Technical Audit with our engineers.