We deploy PostgreSQL natively to execute a decentralized data mesh architecture, proving that multi-million dollar cloud platforms and proprietary vendor ecosystems are infrastructure bloat. By utilizing open-source database primitives, we eliminate dependencies on specific tech conglomerates and cloud provider pricing models. We enforce domain boundaries, query allocations, and data product contracts directly through the PostgreSQL core engine using schemas, foreign data wrappers, and logical replication.
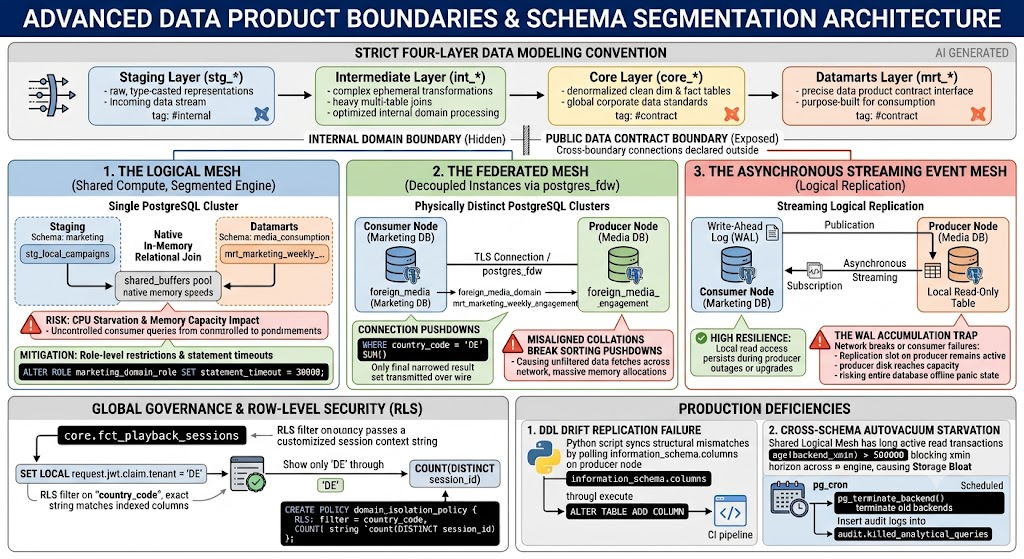
Data Product Boundaries & Schema Segmentation Architecture
We enforce a strict four-layer data modeling convention inside every domain’s storage layout. We configure our dbt-core compilation profiles to validate these layers prior to deployment to production environments.
The storage layout separates raw data processing from public-facing consumption layers to guarantee that schema drift in operational upstream systems does not degrade downstream cross-domain queries.
graph TD
subgraph internal ["Internal Domain Boundary (Hidden)"]
stg[Staging Layer: stg_*]
int[Intermediate Layer: int_*]
stg --> int
end
subgraph public ["Public Data Contract Boundary (Exposed)"]
core[Core Layer: core_*]
mrt[Datamarts Layer: mrt_*]
core --> mrt
end
%% Cross-boundary connections declared outside
int --> core
mrt --> Consumer[External Domain Consumers]
%% Styling
style stg fill:#f9f,stroke:#333,stroke-width:2px
style int fill:#bbf,stroke:#333,stroke-width:2px
style core fill:#bfb,stroke:#333,stroke-width:4px
style mrt fill:#fbf,stroke:#333,stroke-width:4px- Staging Layer (
stg_): Contains raw, type-casted representations of upstream operational tables. External query roles are blocked from accessing this layer. - Intermediate Layer (
int_): Holds complex ephemeral transformations, heavy multi-table joins, and business logic calculations. It is optimized for internal domain processing speed. - Core Layer (
core_): Represents denormalized, clean dimension and fact tables that conform to global corporate data standards. - Datamarts Layer (
mrt_): Serves as the precise data product contract interface. These tables are purpose-built for consumption by outside domains and business intelligence systems.
We enforce these boundaries at the dbt orchestration layer using schema-level configurations. Below is the configuration manifest (dbt_project.yml) we deployed to enforce this layer isolation across our repositories:
name: 'media_consumption_domain'
version: '2.4.0'
config-version: 2
models:
media_consumption_domain:
staging:
+materialized: view
+schema: internal_stg
+tags: ["internal"]
intermediate:
+materialized: ephemeral
+tags: ["internal"]
core:
+materialized: table
+schema: public_core
+tags: ["contract"]
datamarts:
+materialized: table
+schema: public_mrt
+tags: ["contract"]
+contract:
enforced: true
When contract: enforced: true is enabled, the dbt compiler runs a pre-compilation check against the database information schema. If a deployment script attempts to alter a data type or drop a column explicitly exposed in the mrt_ layer, the compilation fails, blocking the deployment pipeline before changes hit production storage.
Mechanism 1: The Logical Mesh (Shared Compute, Segmented Engine)
When domains require minimal network latency access to shared data products and run within the same physical infrastructure boundaries, we deploy a single-cluster, multi-schema architecture.
In this setup, different domain pipelines run on decoupled codebases and independent schedules, executing within isolated database schemas on a single PostgreSQL instance.
graph LR
subgraph Single PostgreSQL Cluster
subgraph Schema: media_consumption
mrt[mrt_marketing_weekly_engagement]
end
subgraph Schema: marketing
stg[stg_local_campaigns]
end
end
stg --> Join[Native In-Memory Relational Join]
mrt --> JoinDuring concurrent read operations, cross-schema queries execute at native memory speeds within the shared_buffers pool. However, this model introduces a critical risk: an unindexed query or an uncontrolled Cartesian product executed by a consuming domain directly impacts the host domain’s CPU allocation and memory capacity.
To mitigate this, we enforce role-level restrictions and statement timeout variables at the user session level.
Execution Script: Schema Creation and Cross-Domain Access Control
-- Executed by central platform administration account
CREATE ROLE marketing_domain_role;
CREATE ROLE media_consumption_domain_role;
ALTER ROLE marketing_domain_role SET statement_timeout = 30000;
ALTER ROLE marketing_domain_role SET work_mem = '128MB';
-- Executed by media_consumption pipeline to provision the schema
CREATE SCHEMA media_consumption;
ALTER SCHEMA media_consumption OWNER TO media_consumption_domain_role;
-- Enforce strict containment: hide internal staging and intermediate structures
REVOKE ALL ON SCHEMA media_consumption FROM PUBLIC;
GRANT USAGE ON SCHEMA media_consumption TO marketing_domain_role;
-- Define explicit data product contract structures
CREATE TABLE media_consumption.mrt_marketing_weekly_engagement (
playback_week DATE NOT NULL,
subscription_tier VARCHAR(32) NOT NULL,
country_code VARCHAR(10) NOT NULL,
weekly_events BIGINT NOT NULL,
weekly_viewtime_seconds BIGINT NOT NULL,
CONSTRAINT pk_mrt_marketing_weekly_engagement PRIMARY KEY (playback_week, subscription_tier, country_code)
);
CREATE INDEX idx_mrt_media_country ON media_consumption.mrt_marketing_weekly_engagement (country_code);
ALTER TABLE media_consumption.mrt_marketing_weekly_engagement OWNER TO media_consumption_domain_role;
-- Authorize the external consumer to access the specific data product contract view
GRANT SELECT ON TABLE media_consumption.mrt_marketing_weekly_engagement TO marketing_domain_role;
-- Executed by marketing domain pipeline to read and join data natively
SET ROLE marketing_domain_role;
SELECT
mrt.playback_week,
mrt.subscription_tier,
mrt.weekly_viewtime_seconds,
local_promo.campaign_id,
local_promo.budget_allocated
FROM media_consumption.mrt_marketing_weekly_engagement mrt
INNER JOIN marketing.stg_local_campaigns local_promo
ON mrt.country_code = local_promo.target_country
WHERE mrt.playback_week >= '2026-01-01'::date;
Mechanism 2: The Federated Mesh (Decoupled Instances via Foreign Data Wrappers)
When separate business units require absolute infrastructure isolation—including dedicated hardware, separate storage ceilings, and independent maintenance windows—we deploy physically distinct PostgreSQL clusters across different nodes.
To query across these boundaries without running external extraction routines, we configure postgres_fdw (Foreign Data Wrapper).
graph LR
subgraph Consumer Node: Marketing DB
foreign_schema[foreign_media_domain]
end
subgraph Producer Node: Media DB
mrt_table[mrt_marketing_weekly_engagement]
end
foreign_schema -- TLS Connection / postgres_fdw --> mrt_tableTo prevent query execution plans from dragging unfiltered rows across the network interface, we configure connection pushdowns.
When the local query planner evaluates a statement, it forces the WHERE clauses and aggregate filters down to the remote database machine, executing the computation on the producer node and transmitting only the final narrowed result set over the wire.
Configuration Script: Remote Connection and Foreign Table Mapping
-- Executed on the Consumer (Marketing) PostgreSQL Cluster
CREATE EXTENSION IF NOT EXISTS postgres_fdw;
-- Configure the remote connection pooling options
CREATE SERVER media_consumption_node
FOREIGN DATA WRAPPER postgres_fdw
OPTIONS (
host 'media-prod-db.internal',
port '5432',
dbname 'media_analytics',
fetch_size '50000',
updatable 'false'
);
-- Map the local system user to the remote authenticated credential
CREATE USER MAPPING FOR marketing_application_user
SERVER media_consumption_node
OPTIONS (
user 'marketing_mesh_consumer',
password 'SecureToken2026!77592_Prod'
);
CREATE SCHEMA foreign_media_domain;
ALTER SCHEMA foreign_media_domain OWNER TO marketing_application_user;
-- Import the specific verified data product interface
IMPORT FOREIGN SCHEMA media_consumption
LIMIT TO (mrt_marketing_weekly_engagement)
FROM SERVER media_consumption_node
INTO foreign_media_domain;
-- Validate the query execution path to ensure remote pushdown occurs
EXPLAIN ANALYZE
SELECT
country_code,
SUM(weekly_viewtime_seconds) as total_seconds
FROM foreign_media_domain.mrt_marketing_weekly_engagement
WHERE country_code = 'DE'
GROUP BY country_code;
The query planner output verifies that the filter executes on the remote instance:
Foreign Scan on mrt_marketing_weekly_engagement (cost=100.00..150.45 rows=25 width=40) (actual time=6.12..6.45 rows=1 loops=1)
Relations: Aggregate on (media_consumption.mrt_marketing_weekly_engagement)
Remote SQL: SELECT country_code, sum(weekly_viewtime_seconds) FROM media_consumption.mrt_marketing_weekly_engagement WHERE ((country_code = 'DE')) GROUP BY country_code
The Collation Failure Mode
We observed severe performance degradation when executing joins across foreign tables containing text columns. If the local instance uses a different database collation order (e.g., en_US.utf8) than the remote cluster (e.g., C.utf8), the PostgreSQL query planner cannot guarantee identical sorting behavior.
As a result, it completely disables remote pushdown execution. It fetches the entire dataset unfiltered across the network to perform the join operations in local volatile memory.
To prevent this degradation in processing time, we explicitly match character sorting settings during cluster initialization across all domain environments.
Mechanism 3: The Asynchronous Streaming Event Mesh (Logical Replication)
When cross-domain query throughput escalates and analytical processing patterns involve heavy, repetitive scans that degrade remote node performance, live federation over a foreign data wrapper causes system failures.
To achieve complete storage and compute independence, we deploy streaming logical replication. This architecture continually pushes real-time transactional updates from the producer’s write-ahead log (WAL) directly into the consumer’s local storage engine.
graph LR
subgraph Producer Node
wal[Write-Ahead Log: WAL] --> pub[Publication]
end
subgraph Consumer Node
sub[Subscription] --> local_storage[Local Read-Only Table]
end
pub -- Asynchronous Streaming --> subThis model provides high resilience. If the producer node undergoes a minor version upgrade or encounters an infrastructure outage, the consumer node continues processing analytical workloads uninterrupted from its local disk replica. Once connectivity restores, the logical replication workers automatically catch up to the current WAL log sequence number (LSN).
Server Tuning Parameters (postgresql.conf)
We enforce identical execution configurations on both the replication producer and consumer nodes to allocate sufficient worker tracks for the stream:
# Core parameter tuning for logical stream processing
wal_level = logical
max_wal_senders = 16
max_replication_slots = 16
max_worker_processes = 32
max_logical_replication_workers = 12
Implementation Script: Publication and Target Sync Routing
-- ====================================================================
-- PHASE 1: EXECUTED ON THE PRODUCER NODE (Media Consumption Instance)
-- ====================================================================
-- Ensure the replication identity is assigned before setting up publication
ALTER TABLE media_consumption.mrt_marketing_weekly_engagement REPLICA IDENTITY DEFAULT;
-- Instantiate the explicit public contract stream
CREATE PUBLICATION pub_marketing_weekly_metrics
FOR TABLE media_consumption.mrt_marketing_weekly_engagement;
-- Register a dedicated user role with narrow replication system rights
CREATE ROLE replica_user WITH REPLICATION LOGIN PASSWORD 'Tokens_2026_SecureSync!';
GRANT USAGE ON SCHEMA media_consumption TO replica_user;
GRANT SELECT ON TABLE media_consumption.mrt_marketing_weekly_engagement TO replica_user;
-- ====================================================================
-- PHASE 2: EXECUTED ON THE CONSUMER NODE (Marketing Instance)
-- ====================================================================
CREATE SCHEMA shared_products;
-- Create an identical target skeleton table matching the data product contract
CREATE TABLE shared_products.mrt_media_weekly_engagement (
playback_week DATE NOT NULL,
subscription_tier VARCHAR(32) NOT NULL,
country_code VARCHAR(10) NOT NULL,
weekly_events BIGINT NOT NULL,
weekly_viewtime_seconds BIGINT NOT NULL,
CONSTRAINT pk_shared_mrt_media PRIMARY KEY (playback_week, subscription_tier, country_code)
);
-- Initialize the streaming subscriber link
CREATE SUBSCRIPTION sub_marketing_metrics
CONNECTION 'host=media-prod-db.internal port=5432 dbname=media_analytics user=replica_user password=Tokens_2026_SecureSync!'
PUBLICATION pub_marketing_weekly_metrics
WITH (
copy_data = true,
create_slot = true,
slot_name = 'sub_marketing_metrics_slot'
);
The WAL Accumulation Trap
We monitor a severe system vulnerability concerning network connection drops or consumer-side table updates. If the consumer subscription enters an un-operational state (e.g., due to a physical network breakdown or a schema type incompatibility), the replication slot on the producer node remains active.
PostgreSQL guarantees data preservation by storing all unacknowledged WAL segments on the producer’s local disk until the consumer acknowledges processing them. If the replication lag is not resolved, the producer node’s disk reaches capacity, forcing the entire database cluster into an unrecoverable offline panic state.
Global Governance and Row-Level Security Execution
A decentralized architecture requires uniform security policy controls. If multiple localized divisions or external teams query a single core analytical tracking table, we do not provision separate tables or specialized filtered views for every group.
Instead, we enforce access restrictions directly at the database engine level via Row-Level Security (RLS).
We avoided embedding pg_has_role() lookups directly inside our security filters. Querying the system catalog introduces a performance overhead per row check during large scans. Instead, we pass a customized session context string variable directly into memory. The storage engine processes this variable using exact string match operations against indexed columns.
-- Enforce engine control filters on the primary fact structure
ALTER TABLE core.fct_playback_sessions ENABLE ROW LEVEL SECURITY;
-- Construct a global security policy mapped directly to domain session variables
CREATE POLICY domain_isolation_policy ON core.fct_playback_sessions
AS RESTRICTIVE
USING (
country_code = current_setting('request.jwt.claim.tenant', true)
OR
current_setting('request.jwt.claim.role', true) = 'global_corporate_audit'
);
When an analytical user or automated application engine initializes a database thread pool connection, it issues a pair of parameters before running any downstream aggregation queries:
-- Session configuration step executed by connection pool controller
SET LOCAL request.jwt.claim.tenant = 'DE';
SET LOCAL request.jwt.claim.role = 'regional_analyst';
-- Executed query automatically reads data matching the assigned token parameter
SELECT
playback_week,
COUNT(DISTINCT session_id) as total_sessions
FROM core.fct_playback_sessions
GROUP BY playback_week;
Summary Matrix: Infrastructure Selection Criteria
We use this structural evaluation index across our engineering teams to match business requirements with the appropriate database primitive:
| Sharing Mechanism | Compute Isolation | Network Latency | Storage Overhead | Primary Operational Trade-off |
| Logical Mesh (Schemas) | None (Shared Cluster) | In-Memory | Zero | Consumer execution choices can cause CPU starvation across unrelated domains. |
Federated Mesh (postgres_fdw) | Complete Partitioning | On-Demand Network | Zero | Misaligned collations break sorting pushdowns, causing massive memory allocations. |
| Event Mesh (Logical Replication) | Complete Partitioning | Asynchronous Local | Dual Storage Cost | Network or subscription failures risk locking the producer’s WAL, risking disk exhaustion. |
Unresolved Production Deficiencies
Our platform infrastructure is not completely resolved. We are currently maintaining two core workarounds across our production environment:
1. DDL Drift Replication Failure
PostgreSQL’s logical streaming replication engine only streams data modification operations (INSERT, UPDATE, DELETE, TRUNCATE). It does not natively parse or replicate Data Definition Language statements (ALTER TABLE, DROP COLUMN, ADD COLUMN).
If a source system team introduces an unannounced schema evolution step, the consumer subscription process crashes instantly with a structural mismatch error, halting real-time synchronization.
We work around this issue using a custom-built Python migration interceptor script that runs every 60 seconds inside our continuous integration pipelines. This script polls the master system catalog of the producer node, checks for schema structural deviations against the consumer data structure, and executes matching ALTER operations through a loop.
Python
import psycopg2
import sys
def sync_schema_drift():
producer_conn = psycopg2.connect("host=media-prod-db.internal dbname=media_analytics user=db_monitor password=Secret")
consumer_conn = psycopg2.connect("host=marketing-db.internal dbname=marketing_analytics user=db_admin password=Secret")
prod_cursor = producer_conn.cursor()
cons_cursor = consumer_conn.cursor()
query = """
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_schema = 'media_consumption'
AND table_name = 'mrt_marketing_weekly_engagement';
"""
prod_cursor.execute(query)
prod_cols = {row[0]: row[1] for row in prod_cursor.fetchall()}
cons_cursor.execute("""
SELECT column_name, data_type
FROM information_schema.columns
WHERE table_schema = 'shared_products'
AND table_name = 'mrt_media_weekly_engagement';
""")
cons_cols = {row[0]: row[1] for row in cons_cursor.fetchall()}
for col, d_type in prod_cols.items():
if col not in cons_cols:
alter_cmd = f"ALTER TABLE shared_products.mrt_media_weekly_engagement ADD COLUMN {col} {d_type};"
cons_cursor.execute(alter_cmd)
consumer_conn.commit()
prod_conn.close()
cons_conn.close()
if __name__ == "__main__":
sync_schema_drift()
2. Cross-Schema Autovacuum Starvation
In our Logical Mesh topology (Single Cluster, Multi-Schema), all schemas share a unified global system transaction catalog. When an active read operation holds open a cursor or transaction inside an analytical schema, it blocks the global minimum transaction ID (xmin) horizon across the entire physical engine.
While that transaction remains open, the database engine’s core autovacuum workers cannot clean up deleted or updated row versions (dead tuples) in other schemas. This results in storage bloat and performance degradation for completely unrelated domain pipelines.
We handle this using a destructive cron-driven kill routine. The script searches the pg_stat_activity catalog every 5 minutes and terminates any active read operation in the database that is older than 500,000 transactions:
SELECT
pg_terminate_backend(pid),
age(backend_xmin),
query
FROM pg_stat_activity
WHERE state != 'idle'
AND backend_xmin IS NOT NULL
AND age(backend_xmin) > 500000;
We encapsulate this SQL logic into a native pg_cron automation loop to handle execution context without relying on external operating system schedulers.
-- Register the automated query termination worker inside the utility schema
SELECT cron.schedule(
'autovacuum_starvation_mitigation',
'*/5 * * * *',
$$
WITH terminated_backends AS (
SELECT
pid,
query,
age(backend_xmin) as xmin_age
FROM pg_stat_activity
WHERE state != 'idle'
AND backend_xmin IS NOT NULL
AND age(backend_xmin) > 500000
),
kill_execution AS (
SELECT pg_terminate_backend(pid) FROM terminated_backends
)
INSERT INTO audit.killed_analytical_queries (terminated_at, pid, xmin_age, query_text)
SELECT clock_timestamp(), pid, xmin_age, query FROM terminated_backends;
$$
);
This operational override forces consuming domains to refactor their analytical workloads into smaller processing windows, ensuring that cross-schema query patterns do not compromise the physical storage performance of the shared cluster core.