AI Agent Workflows: Pydantic AI
Building Intelligent Multi-Agent Systems with Pydantic AI In the rapidly evolving landscape of artificial intelligence, multi-agent systems have emerged as a powerful... Read more.
The Ultimate Vector Database Showdown: A Performance and Cost Deep Dive on AWS
In the age of AI, Retrieval-Augmented Generation (RAG) is king. The engine powering this revolution? The vector database. Choosing the right one is critical for... Read more.
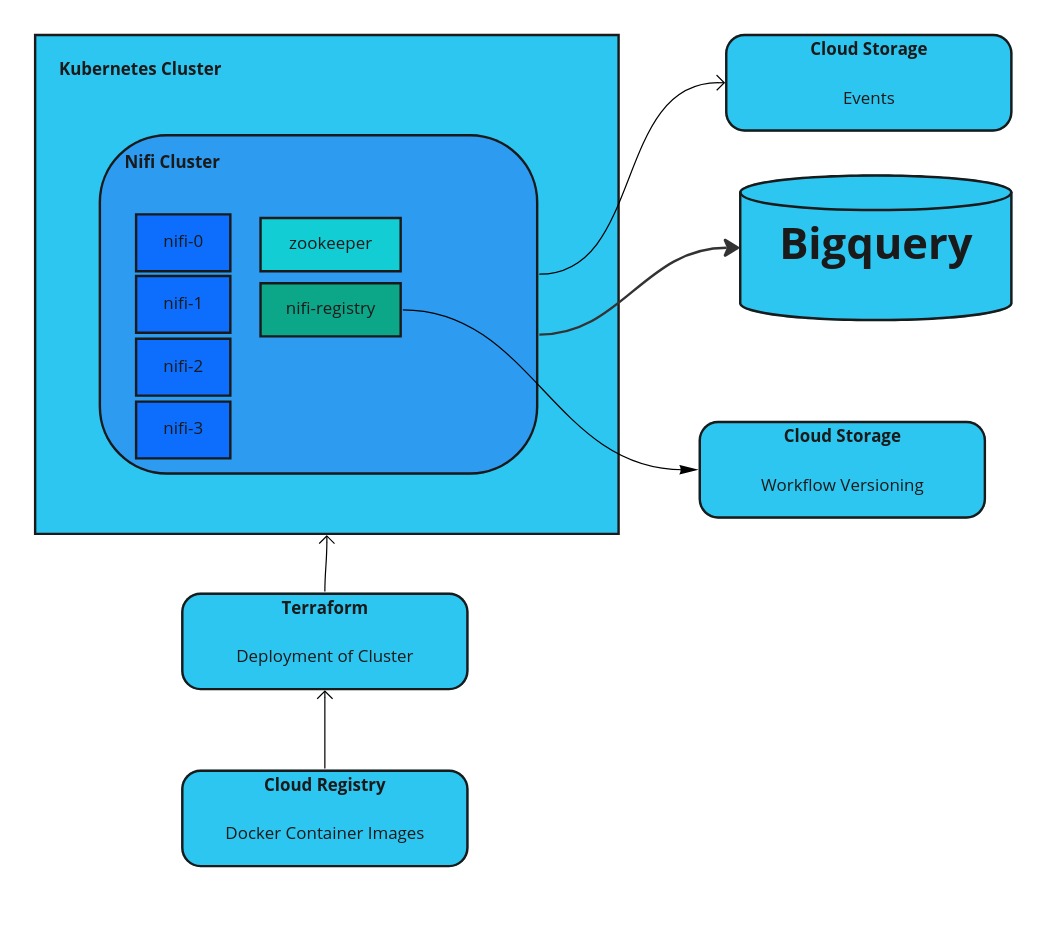
Apache Nifi on Google Cloud Kubernetes Engine (GKE)
Apache Nifi on GKE can be a good solution, if you want to have a low code solution for processing streaming data. If you set it up on GKE, a managed version of Kubernetes,... Read more.
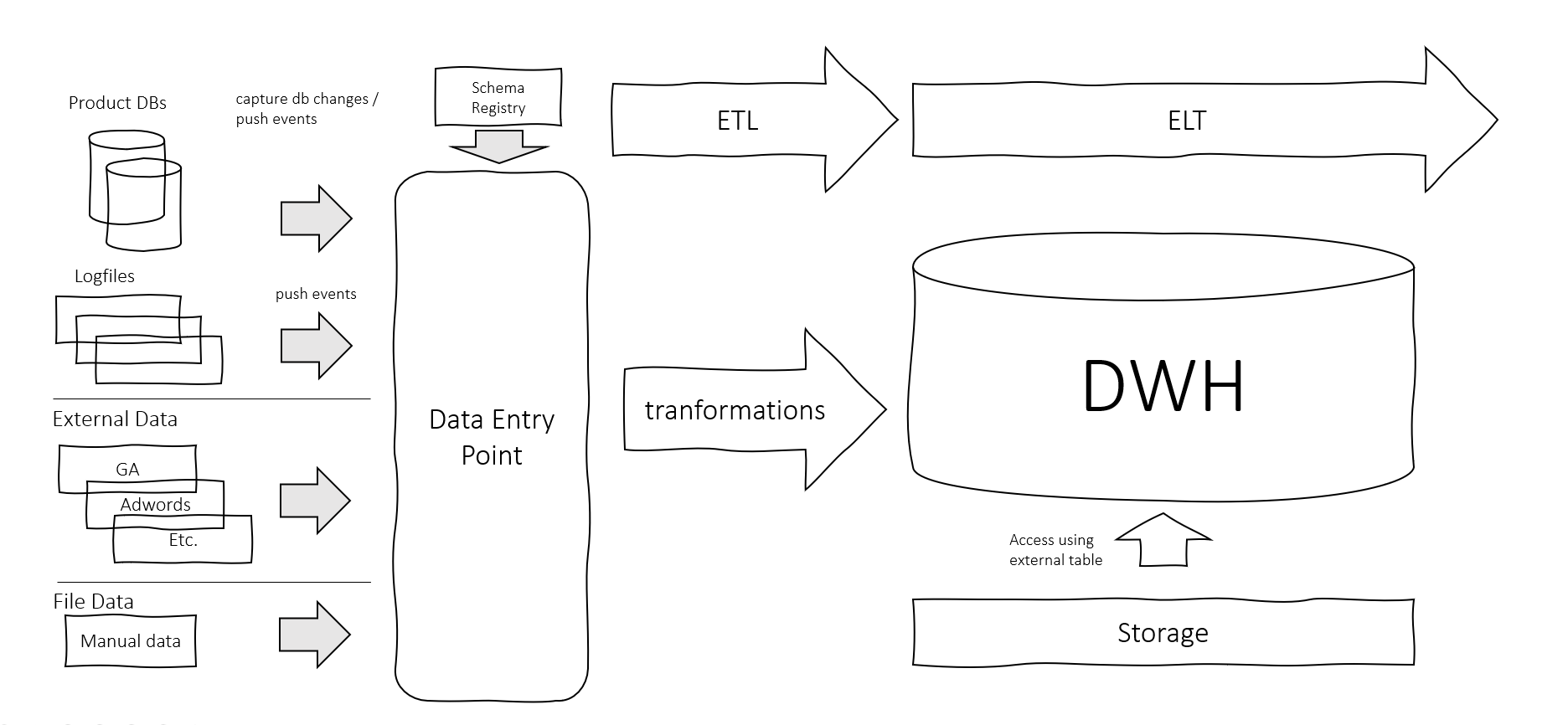
Data Infrastructure in the Cloud
Having your data infrastructure in the cloud has become a real option for a lot of companies, especially since the big cloud providers have a lot of managed services... Read more.
Bringing machine learning models into production
Developing and bringing machine learning models into production is a task with a lot of challenges. These include model and attribute selection, dealing with missing... Read more.

Google Cloud Data Engineer Exam Preparation
This is a little text with all the stuff that helped me prepare for the Google Cloud Data Engineer Exam. There are a lot of courses and resources, that help you... Read more.
AVRO schema generation with reusable fields
Why use AVRO and AVRO Schema? There are several serialized file formats out there, so chosing the one most suited for your needs is crucial. This blog entry will... Read more.
Plumber: Getting R ready for production environments?
R Project and Production Running R Project in production is a controversially discussed topic, as is everything concerning R vs Python. Lately there have been some... Read more.
Analytics Platform: An Evolution from Data Lake
Analytics Platform Having built a Data Lake for your company’s analytical needs, there soon will arise new use cases, that cannot be easily covered with the... Read more.
Building a Productive Data Lake: How to keep three systems in sync
Three Systems for save Development When you are building a productive Data Lake it is important to have at least three environments: Development: for development,... Read more.